- FAQ
- Quickstart
- Setup & Configuration
- Programming Guides
- Examples
- Execution
- Internals
Java API Programming Guide
-
Java API
- Introduction
- Example Program
- Linking with Stratosphere
- Program Skeleton
- Lazy Evaluation
- Data Types
- Data Transformations
- Data Sources
- Data Sinks
- Debugging
- Iteration Operators
- Semantic Annotations
- Broadcast Variables
- Program Packaging & Distributed Execution
- Accumulators & Counters
- Execution Plans
Java API
Introduction
Analysis programs in Stratosphere are regular Java programs that implement transformations on data sets (e.g., filtering, mapping, joining, grouping). The data sets are initially created from certain sources (e.g., by reading files, or from collections). Results are returned via sinks, which may for example write the data to (distributed) files, or to standard output (for example the command line terminal). Stratosphere programs run in a variety of contexts, standalone, or embedded in other programs. The execution can happen in a local JVM, or on clusters of many machines.
In order to create your own Stratosphere program, we encourage you to start with the program skeleton and gradually add your own transformations. The remaining sections act as references for additional operations and advanced features.
Example Program
The following program is a complete, working example of WordCount. You can copy & paste the code to run it locally. You only have to include Stratosphere's Java API library into your project (see Section Linking with Stratosphere) and specify the imports. Then you are ready to go!
public class WordCountExample {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?");
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.aggregate(Aggregations.SUM, 1);
wordCounts.print();
env.execute("Word Count Example");
}
public static final class LineSplitter extends FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
Linking with Stratosphere
To write programs with Stratosphere, you need to include Stratosphere’s Java API library in your project.
The simplest way to do this is to use the quickstart scripts. They create a blank project from a template (a Maven Archetype), which sets up everything for you. To manually create the project, you can use the archetype and create a project by calling:
mvn archetype:generate /
-DarchetypeGroupId=eu.stratosphere /
-DarchetypeArtifactId=quickstart-java /
-DarchetypeVersion=0.5.1
If you want to add Stratosphere to an existing Maven project, add the following entry to your dependencies section in the pom.xml file of your project:
<dependency>
<groupId>eu.stratosphere</groupId>
<artifactId>stratosphere-java</artifactId>
<version>0.5.1</version>
</dependency>
<dependency>
<groupId>eu.stratosphere</groupId>
<artifactId>stratosphere-clients</artifactId>
<version>0.5.1</version>
</dependency>
In order to link against the latest SNAPSHOT versions of the code, please follow this guide.
The stratosphere-clients dependency is only necessary to invoke the Stratosphere program locally (for example to run it standalone for testing and debugging). If you intend to only export the program as a JAR file and run it on a cluster, you can skip that dependency.
Program Skeleton
As we already saw in the example, Stratosphere programs look like regular Java
programs with a main() method. Each program consists of the same basic parts:
- Obtain an
ExecutionEnvironment, - Load/create the initial data,
- Specify transformations on this data,
- Specify where to put the results of your computations, and
- Execute your program.
We will now give an overview of each of those steps but please refer
to the respective sections for more details. Note that all core classes of the Java API are found in the package eu.stratosphere.api.java.
The ExecutionEnvironment is the basis for all Stratosphere programs. You can
obtain one using these static methods on class ExecutionEnvironment:
getExecutionEnvironment()
createLocalEnvironment()
createLocalEnvironment(int degreeOfParallelism)
createRemoteEnvironment(String host, int port, String... jarFiles)
createRemoteEnvironment(String host, int port, int degreeOfParallelism, String... jarFiles)
Typically, you only need to use getExecutionEnvironment(), since this
will do the right thing depending on the context: if you are executing
your program inside an IDE or as a regular Java program it will create
a local environment that will execute your program on your local machine. If
you created a JAR file from you program, and invoke it through the command line
or the web interface,
the Stratosphere cluster manager will
execute your main method and getExecutionEnvironment() will return
an execution environment for executing your program on a cluster.
For specifying data sources the execution environment has several methods to read from files using various methods: you can just read them line by line, as CSV files, or using completely custom data input formats. To just read a text file as a sequence of lines, you could use:
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.readTextFile("file:///path/to/file");
This will give you a DataSet on which you can then apply transformations. For
more information on data sources and input formats, please refer to
Data Sources.
Once you have a DataSet you can apply transformations to create a new
DataSet which you can then write to a file, transform again, or
combine with other DataSets. You apply transformations by calling
methods on DataSet with your own custom transformation function. For example,
map looks like this:
DataSet<String> input = ...;
DataSet<Integer> tokenized = text.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) {
return Integer.parseInt(value);
}
});
This will create a new DataSet by converting every String in the original
set to an Integer. For more information and a list of all the transformations,
please refer to Transformations.
Once you have a DataSet that needs to be written to disk you call one
of these methods on DataSet:
writeAsText(String path)
writeAsCsv(String path)
write(FileOutputFormat<T> outputFormat, String filePath)
print()
The last method is only useful for developing/debugging on a local machine,
it will output the contents of the DataSet to standard output. (Note that in
a cluster, the result goes to the standard out stream of the cluster nodes and ends
up in the .out files of the workers).
The first two do as the name suggests, the third one can be used to specify a
custom data output format. Keep in mind, that these calls do not actually
write to a file yet. Only when your program is completely specified and you
call the execute method on your ExecutionEnvironment are all the
transformations executed and is data written to disk. Please refer
to Data Sinks for more information on writing to files and also
about custom data output formats.
Once you specified the complete program you need to call execute on
the ExecutionEnvironment. This will either execute on your local
machine or submit your program for execution on a cluster, depending on
how you created the execution environment.
Back to top
Lazy Evaluation
All Stratosphere programs are executed lazily: When the program's main method is executed, the data loading and transformations do not happen directly. Rather, each operation is created and added to the program's plan. The operations are actually executed when one of the execute() methods is invoked on the ExecutionEnvironment object. Whether the program is executed locally or on a cluster depends on the environment of the program.
The lazy evaluation lets you construct sophisticated programs that Stratosphere executes as one holistically planned unit.
Data Types
The Java API is strongly typed: All data sets and transformations accept typed elements. This catches type errors very early and supports safe refactoring of programs. The API supports various different data types for the input and output of operators. Both DataSet and functions like MapFunction, ReduceFunction, etc. are parameterized with data types using Java generics in order to ensure type-safety.
There are four different categories of data types, which are treated slightly different:
- Regular Types
- Tuples
- Values
- Hadoop Writables
Regular Types
Out of the box, the Java API supports all common basic Java types: Byte, Short, Integer, Long, Float, Double, Boolean, Character, String.
Furthermore, you can use the vast majority of custom Java classes. Restrictions apply to classes containing fields that cannot be serialized, like File pointers, I/O streams, or other native resources. Classes that follow the Java Beans conventions work well in general. The following defines a simple example class to illustrate how you can use custom classes:
public class WordWithCount {
public String word;
public int count;
public WordCount() {}
public WordCount(String word, int count) {
this.word = word;
this.count = count;
}
}
You can use all of those types to parameterize DataSet and function implementations, e.g. DataSet<String> for a String data set or MapFunction<String, Integer> for a mapper from String to Integer.
// using a basic data type
DataSet<String> numbers = env.fromElements("1", "2");
numbers.map(new MapFunction<String, Integer>() {
@Override
public String map(String value) throws Exception {
return Integer.parseInt(value);
}
});
// using a custom class
DataSet<WordCount> wordCounts = env.fromElements(
new WordCount("hello", 1),
new WordCount("world", 2));
wordCounts.map(new MapFunction<WordCount, Integer>() {
@Override
public String map(WordCount value) throws Exception {
return value.count;
}
});
When working with operators that require a Key for grouping or matching records
you need to implement a KeySelector for your custom type (see
Section Data Transformations).
wordCounts.groupBy(new KeySelector<WordCount, String>() {
public String getKey(WordCount v) {
return v.word;
}
}).reduce(new MyReduceFunction());
Tuples
You can use the Tuple classes for composite types. Tuples contain a fix number of fields of various types. The Java API provides classes from Tuple1 up to Tuple25. Every field of a tuple can be an arbitrary Stratosphere type - including further tuples, resulting in nested tuples. Fields of a Tuple can be accessed directly using the fields tuple.f4, or using the generic getter method tuple.getField(int position). The field numbering starts with 0. Note that this stands in contrast to the Scala tuples, but it is more consistent with Java's general indexing.
DataSet<Tuple2<String, Integer>> wordCounts = env.fromElements(
new Tuple2<String, Integer>("hello", 1),
new Tuple2<String, Integer>("world", 2));
wordCounts.map(new MapFunction<Tuple2<String, Integer>, Integer>() {
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
return value.f1;
}
});
When working with operators that require a Key for grouping or matching records, Tuples let you simply specify the positions of the fields to be used as key. You can specify more than one position to use composite keys (see Section Data Transformations).
wordCounts
.groupBy(0)
.reduce(new MyReduceFunction());
In order to access fields more intuitively and to generate more readable code, it is also possible to extend a subclass of Tuple. You can add getters and setters with custom names that delegate to the field positions. See this example for an illustration how to make use of that mechanism.
Values
Value types describe their serialization and deserialization manually. Instead of going through a general purpose serialization framework, they provide custom code for those operations by means implementing the eu.stratosphere.types.Value interface with the methods read and write. Using a Value type is reasonable when general purpose serialization would be highly inefficient. An example would be a data type that implements a sparse vector of elements as an array. Knowing that the array is mostly zero, one can use a special encoding for the non-zero elements, while the general purpose serialization would simply write all array elements.
The eu.stratosphere.types.CopyableValue interface supports manual internal cloning logic in a similar way.
Stratosphere comes with pre-defined Value types that correspond to Java's basic data types. (ByteValue, ShortValue, IntValue, LongValue, FloatValue, DoubleValue, StringValue, CharValue, BooleanValue). These Value types act as mutable variants of the basic data types: Their value can be altered, allowing programmers to reuse objects and take pressure off the garbage collector.
Hadoop Writables
You can use types that implement the org.apache.hadoop.Writable interface. The serialization logic defined in the write()and readFields() methods will be used for serialization.
Type Erasure & Type Inferrence
The Java compiler throws away much of the generic type information after the compilation. This is known as type erasure in Java. It means that at runtime, an instance of an object does not know its generic type any more. For example, instances of DataSet<String> and DataSet<Long> look the same to the JVM.
Stratosphere requires type information at the time when it prepares the program for execution (when the main method of the program is called). The Stratosphere Java API tries to reconstruct the type information that was thrown away in various ways and store it explicitly in the data sets and operators. You can retrieve the type via DataSet.getType(). The method returns an instance of TypeInformation, which is Stratosphere's internal way of representing types.
The type inference has its limits and needs the "cooperation" of the programmer in some cases. Examples for that are methods that create data sets from collections, such as ExecutionEnvironment.fromCollection(), where you can pass an argument that describes the type. But also generic functions like MapFunction<I, O> may need extra type information.
The ResultTypeQueryable interface can be implemented by input formats and functions to tell the API explicitly about their return type. The input types that the functions are invoked with can usually be inferred by the result types of the previous operations.
Data Transformations
A data transformation transforms one or more DataSets into a new DataSet. Advanced data analysis programs can be assembled by chaining multiple transformations.
Map
The Map transformation applies a user-defined MapFunction on each element of a DataSet.
It implements a one-to-one mapping, that is, exactly one element must be returned by
the function.
The following code transforms a DataSet of Integer pairs into a DataSet of Integers:
// MapFunction that adds two integer values
public class IntAdder extends MapFunction<Tuple2<Integer, Integer>, Integer> {
@Override
public Integer map(Tuple2<Integer, Integer> in) {
return in.f0 + in.f1;
}
}
// [...]
DataSet<Tuple2<Integer, Integer>> intPairs = // [...]
DataSet<Integer> intSums = intPairs.map(new IntAdder());
FlatMap
The FlatMap transformation applies a user-defined FlatMapFunction on each element of a DataSet.
This variant of a map function can return arbitrary many result elements (including none) for each input element.
The following code transforms a DataSet of text lines into a DataSet of words:
// FlatMapFunction that tokenizes a String by whitespace characters and emits all String tokens.
public class Tokenizer extends FlatMapFunction<String, String> {
@Override
public void flatMap(String value, Collector<String> out) {
for (String token : value.split("\\W")) {
out.collect(token);
}
}
}
// [...]
DataSet<String> textLines = // [...]
DataSet<String> words = textLines.flatMap(new Tokenizer());
Filter
The Filter transformation applies a user-defined FilterFunction on each element of a DataSet and retains only those elements for which the function returns true.
The following code removes all Integers smaller than zero from a DataSet:
// FilterFunction that filters out all Integers smaller than zero.
public class NaturalNumberFilter extends FilterFunction<Integer> {
@Override
public boolean filter(Integer number) {
return number >= 0;
}
}
// [...]
DataSet<Integer> intNumbers = // [...]
DataSet<Integer> naturalNumbers = intNumbers.filter(new NaturalNumberFilter());
Project (Tuple DataSets only)
The Project transformation removes or moves Tuple fields of a Tuple DataSet.
The project(int...) method selects Tuple fields that should be retained by their index and defines their order in the output Tuple.
The types(Class<?> ...)method must give the types of the output Tuple fields.
Projections do not require the definition of a user function.
The following code shows different ways to apply a Project transformation on a DataSet:
DataSet<Tuple3<Integer, Double, String>> in = // [...]
// converts Tuple3<Integer, Double, String> into Tuple2<String, Integer>
DataSet<Tuple2<String, Integer>> out = in.project(2,0).types(String.class, Integer.class);
Transformations on grouped DataSet
The reduce operations can operate on grouped data sets. Specifying the key to be used for grouping can be done in two ways:
- a
KeySelectorfunction or - one or more field position keys (
TupleDataSetonly).
Please look at the reduce examples to see how the grouping keys are specified.
Reduce on grouped DataSet
A Reduce transformation that is applied on a grouped DataSet reduces each group to a single element using a user-defined ReduceFunction.
For each group of input elements, a ReduceFunction successively combines pairs of elements into one element until only a single element for each group remains.
Reduce on DataSet grouped by KeySelector Function
A KeySelector function extracts a key value from each element of a DataSet. The extracted key value is used to group the DataSet.
The following code shows how to group a POJO DataSet using a KeySelector function and to reduce it with a ReduceFunction.
// some ordinary POJO
public class WC {
public String word;
public int count;
// [...]
}
// ReduceFunction that sums Integer attributes of a POJO
public class WordCounter extends ReduceFunction<WC> {
@Override
public WC reduce(WC in1, WC in2) {
return new WC(in1.word, in1.count + in2.count);
}
}
// [...]
DataSet<WC> words = // [...]
DataSet<WC> wordCounts = words
// DataSet grouping with inline-defined KeySelector function
.groupBy(
new KeySelector<WC, String>() {
public String getKey(WC wc) { return wc.word; }
})
// apply ReduceFunction on grouped DataSet
.reduce(new WordCounter());
Reduce on DataSet grouped by Field Position Keys (Tuple DataSets only)
Field position keys specify one or more fields of a Tuple DataSet that are used as grouping keys.
The following code shows how to use field position keys and apply a ReduceFunction.
DataSet<Tuple3<String, Integer, Double>> tuples = // [...]
DataSet<Tuple3<String, Integer, Double>> reducedTuples =
tuples
// group DataSet on first and second field of Tuple
.groupBy(0,1)
// apply ReduceFunction on grouped DataSet
.reduce(new MyTupleReducer());
GroupReduce on grouped DataSet
A GroupReduce transformation that is applied on a grouped DataSet calls a user-defined GroupReduceFunction for each group. The difference
between this and Reduce is that the user defined function gets the whole group at once.
The function is invoked with an iterator over all elements of a group and can return an arbitrary number of result elements using the collector.
GroupReduce on DataSet grouped by Field Position Keys (Tuple DataSets only)
The following code shows how duplicate strings can be removed from a DataSet grouped by Integer.
public class DistinctReduce
extends GroupReduceFunction<Tuple2<Integer, String>, Tuple2<Integer, String>> {
// Set to hold all unique strings of a group
Set<String> uniqStrings = new HashSet<String>();
@Override
public void reduce(Iterator<Tuple2<Integer, String>> in, Collector<Tuple2<Integer, String>> out) {
// clear set
uniqStrings.clear();
// there is at least one element in the iterator
Tuple2<Integer, String> first = in.next();
Integer key = first.f0;
uniqStrings.add(first.f1);
// add all strings of the group to the set
while(in.hasNext()) {
uniqStrings.add(in.next().f1);
}
// emit all unique strings
Tuple2<Integer, String> t = new Tuple2<Integer, String>(key, "");
for(String s : uniqStrings) {
t.f1 = s;
out.collect(t);
}
}
}
// [...]
DataSet<Tuple2<Integer, String>> input = // [...]
DataSet<Tuple2<Integer, String>> output =
input
// group DataSet by the first tuple field
.groupBy(0)
// apply GroupReduceFunction on each group and
// remove elements with duplicate strings.
.reduceGroup(new DistinctReduce());
Note: Stratosphere internally works a lot with mutable objects. Collecting objects like in the above example only works because Strings are immutable in Java!
GroupReduce on DataSet grouped by KeySelector Function
Works analogous to KeySelector functions in Reduce transformations.
GroupReduce on sorted groups (Tuple DataSets only)
A GroupReduceFunction accesses the elements of a group using an iterator. Optionally, the iterator can hand out the elements of a group in a specified order. In many cases this can help to reduce the complexity of a user-defined GroupReduceFunction and improve its efficiency.
Right now, this feature is only available for Tuple DataSet.
The following code shows another example how to remove duplicate Strings in a DataSet grouped by an Integer and sorted by String.
// GroupReduceFunction that removes consecutive identical elements
public class DistinctReduce
extends GroupReduceFunction<Tuple2<Integer, String>, Tuple2<Integer, String>> {
@Override
public void reduce(Iterator<Tuple2<Integer, String>> in, Collector<Tuple2<Integer, String>> out) {
// there is at least one element in the iterator
Tuple2<Integer, String> first = in.next();
Integer key = first.f0;
String comp = first.f1;
// for each element in group
while(in.hasNext()) {
String next = in.next().f1;
// check if strings are different
if(!next.equals(comp)) {
// emit a new element
out.collect(new Tuple2<Integer, String>(key, comp));
// update compare string
comp = next;
}
}
// emit last element
out.collect(new Tuple2<Integer, String>(key, comp));
}
}
// [...]
DataSet<Tuple2<Integer, String>> input = // [...]
DataSet<Double> output = input
// group DataSet by the first tuple field
.groupBy(0)
// sort groups on second tuple field
.sortGroup(1, Order.ASCENDING)
// // apply GroupReduceFunction on DataSet with sorted groups
.reduceGroup(new DistinctReduce());
Note: A GroupSort often comes for free if the grouping is established using a sort-based execution strategy of an operator before the reduce operation.
Combinable GroupReduceFunctions
In contrast to a ReduceFunction, a GroupReduceFunction is not implicitly combinable. In order to make a GroupReduceFunction combinable, you need to implement (override) the combine() method and annotate the GroupReduceFunction with the @Combinable annotation as shown here:
The following code shows how to compute multiple sums using a combinable GroupReduceFunction:
// Combinable GroupReduceFunction that computes two sums.
@Combinable
public class MyCombinableGroupReducer
extends GroupReduceFunction<Tuple3<String, Integer, Double>,
Tuple3<String, Integer, Double>> {
@Override
public void reduce(Iterator<Tuple3<String, Integer, Double>> in,
Collector<Tuple3<String, Integer, Double>> out) {
// one element is always present in iterator
Tuple3<String, Integer, Double> curr = in.next();
String key = curr.f0;
int intSum = curr.f1;
double doubleSum = curr.f2;
// sum up all ints and doubles
while(in.hasNext()) {
curr = in.next();
intSum += curr.f1;
doubleSum += curr.f2;
}
// emit a tuple with both sums
out.collect(new Tuple3<String, Integer, Double>(key, intSum, doubleSum));
}
@Override
public void combine(Iterator<Tuple3<String, Integer, Double>> in,
Collector<Tuple3<String, Integer, Double>> out)) {
// in some cases combine() calls can simply be forwarded to reduce().
this.reduce(in, out);
}
}
Aggregate on grouped Tuple DataSet
There are some common aggregation operations that are frequently used. The Aggregate transformation provides the following build-in aggregation functions:
- Sum,
- Min, and
- Max.
The Aggregate transformation can only be applied on a Tuple DataSet and supports only field positions keys for grouping.
The following code shows how to apply an Aggregation transformation on a DataSet grouped by field position keys:
DataSet<Tuple3<Integer, String, Double>> input = // [...]
DataSet<Tuple3<Integer, String, Double>> output = input
// group DataSet on second field
.groupBy(1)
// compute sum of the first field
.aggregate(SUM, 0)
// compute minimum of the third field
.and(MIN, 2);
To apply multiple aggregations on a DataSet it is necessary to use the .and() function after the first aggregate, that means .aggregate(SUM, 0).and(MIN, 2) produces the sum of field 0 and the minimum of field 2 of the original DataSet.
In contrast to that .aggregate(SUM, 0).aggregate(MIN, 2) will apply an aggregation on an aggregation. In the given example it would produce the minimum of field 2 after calculating the sum of field 0 grouped by field 1.
Note: The set of aggregation functions will be extended in the future.
Reduce on full DataSet
The Reduce transformation applies a user-defined ReduceFunction to all elements of a DataSet.
The ReduceFunction subsequently combines pairs of elements into one element until only a single element remains.
The following code shows how to sum all elements of an Integer DataSet:
// ReduceFunction that sums Integers
public class IntSummer extends ReduceFunction<Integer> {
@Override
public Integer reduce(Integer num1, Integer num2) {
return num1 + num2;
}
}
// [...]
DataSet<Integer> intNumbers = // [...]
DataSet<Integer> sum = intNumbers.reduce(new IntSummer());
Reducing a full DataSet using the Reduce transformation implies that the final Reduce operation cannot be done in parallel. However, a ReduceFunction is automatically combinable such that a Reduce transformation does not limit scalability for most use cases.
GroupReduce on full DataSet
The GroupReduce transformation applies a user-defined GroupReduceFunction on all elements of a DataSet.
A GroupReduceFunction can iterate over all elements of DataSet and return an arbitrary number of result elements.
The following example shows how to apply a GroupReduce transformation on a full DataSet:
DataSet<Integer> input = // [...]
// apply a (preferably combinable) GroupReduceFunction to a DataSet
DataSet<Double> output = input.reduceGroup(new MyGroupReducer());
Note: A GroupReduce transformation on a full DataSet cannot be done in parallel if the GroupReduceFunction is not combinable. Therefore, this can be a very compute intensive operation. See the paragraph on "Combineable GroupReduceFunctions" above to learn how to implement a combinable GroupReduceFunction.
Aggregate on full Tuple DataSet
There are some common aggregation operations that are frequently used. The Aggregate transformation provides the following build-in aggregation functions:
- Sum,
- Min, and
- Max.
The Aggregate transformation can only be applied on a Tuple DataSet.
The following code shows how to apply an Aggregation transformation on a full DataSet:
DataSet<Tuple2<Integer, Double>> input = // [...]
DataSet<Tuple2<Integer, Double>> output = input
// compute sum of the first field
.aggregate(SUM, 0)
// compute minimum of the second field
.and(MIN, 1);
Note: Extending the set of supported aggregation functions is on our roadmap.
Join
The Join transformation joins two DataSets into one DataSet. The elements of both DataSets are joined on one or more keys which can be specified using
- a
KeySelectorfunction or - one or more field position keys (
TupleDataSetonly).
There are a few different ways to perform a Join transformation which are shown in the following.
Default Join (Join into Tuple2)
The default Join transformation produces a new TupleDataSet with two fields. Each tuple holds a joined element of the first input DataSet in the first tuple field and a matching element of the second input DataSet in the second field.
The following code shows a default Join transformation using field position keys:
DataSet<Tuple2<Integer, String>> input1 = // [...]
DataSet<Tuple2<Double, Integer>> input2 = // [...]
// result dataset is typed as Tuple2
DataSet<Tuple2<Tuple2<Integer, String>, Tuple2<Double, Integer>>>
result =
input1.join(input2)
// key definition on first DataSet using a field position key
.where(0)
// key definition of second DataSet using a field position key
.equalTo(1);
Join with JoinFunction
A Join transformation can also call a user-defined JoinFunction to process joining tuples.
A JoinFunction receives one element of the first input DataSet and one element of the second input DataSet and returns exactly one element.
The following code performs a join of DataSet with custom java objects and a Tuple DataSet using KeySelector functions and shows how to call a user-defined JoinFunction:
// some POJO
public class Rating {
public String name;
public String category;
public int points;
}
// Join function that joins a custom POJO with a Tuple
public class PointWeighter
extends JoinFunction<Rating, Tuple2<String, Double>, Tuple2<String, Double>> {
@Override
public Tuple2<String, Double> join(Rating rating, Tuple2<String, Double> weight) {
// multiply the points and rating and construct a new output tuple
return new Tuple2<String, Double>(rating.name, rating.points * weight.f1);
}
}
DataSet<Rating> ratings = // [...]
DataSet<Tuple2<String, Double>> weights = // [...]
DataSet<Tuple2<String, Double>>
weightedRatings =
ratings.join(weights)
// key definition of first DataSet using a KeySelector function
.where(new KeySelection<Rating, String>() {
public String getKey(Rating r) { return r.category; }
})
// key definition of second DataSet using a KeySelector function
.equalTo(new KeySelection<Tuple2<String, Double>, String>() {
public String getKey(Tuple2<String, Double> t) { return t.f0; }
})
// applying the JoinFunction on joining pairs
.with(new PointWeighter());
Join with Projection
A Join transformation can construct result tuples using a projection as shown here:
DataSet<Tuple3<Integer, Byte, String>> input1 = // [...]
DataSet<Tuple2<Integer, Double>> input2 = // [...]
DataSet<Tuple4<Integer, String, Double, Byte>
result =
input1.join(input2)
// key definition on first DataSet using a field position key
.where(0)
// key definition of second DataSet using a field position key
.equalTo(0)
// select and reorder fields of matching tuples
.projectFirst(0,2).projectSecond(1).projectFirst(1)
.types(Integer.class, String.class, Double.class, Byte.class);
projectFirst(int...) and projectSecond(int...) select the fields of the first and second joined input that should be assembled into an output Tuple. The order of indexes defines the order of fields in the output tuple.
The join projection works also for non-Tuple DataSets. In this case, projectFirst() or projectSecond() must be called without arguments to add a joined element to the output Tuple.
Join with DataSet Size Hint
In order to guide the optimizer to pick the right execution strategy, you can hint the size of a DataSet to join as shown here:
DataSet<Tuple2<Integer, String>> input1 = // [...]
DataSet<Tuple2<Integer, String>> input2 = // [...]
DataSet<Tuple2<Tuple2<Integer, String>, Tuple2<Integer, String>>>
result1 =
// hint that the second DataSet is very small
input1.joinWithTiny(input2)
.where(0)
.equalTo(0);
DataSet<Tuple2<Tuple2<Integer, String>, Tuple2<Integer, String>>>
result2 =
// hint that the second DataSet is very large
input1.joinWithHuge(input2)
.where(0)
.equalTo(0);
Cross
The Cross transformation combines two DataSets into one DataSet. It builds all pairwise combinations of the elements of both input DataSets, i.e., it builds a Cartesian product.
The Cross transformation either calls a user-defined CrossFunction on each pair of elements or applies a projection. Both modes are shown in the following.
Note: Cross is potentially a very compute-intensive operation which can challenge even large compute clusters!
Cross with User-Defined Function
A Cross transformation can call a user-defined CrossFunction. A CrossFunction receives one element of the first input and one element of the second input and returns exactly one result element.
The following code shows how to apply a Cross transformation on two DataSets using a CrossFunction:
public class Coord {
public int id;
public int x;
public int y;
}
// CrossFunction computes the Euclidean distance between two Coord objects.
public class EuclideanDistComputer
extends CrossFunction<Coord, Coord, Tuple3<Integer, Integer, Double>> {
@Override
public Tuple3<Integer, Integer, Double> cross(Coord c1, Coord c2) {
// compute Euclidean distance of coordinates
double dist = Math.sqrt(Math.pow(c1.x - c2.x, 2) + Math.pow(c1.y - c2.y, 2));
return new Tuple3<Integer, Integer, Double>(c1.id, c2.id, dist);
}
}
DataSet<Coord> coords1 = // [...]
DataSet<Coord> coords2 = // [...]
DataSet<Tuple3<Integer, Integer, Double>>
distances =
coords1.cross(coords2)
// apply CrossFunction
.with(new EuclideanDistComputer());
Cross with Projection
A Cross transformation can also construct result tuples using a projection as shown here:
DataSet<Tuple3<Integer, Byte, String>> input1 = // [...]
DataSet<Tuple2<Integer, Double>> input2 = // [...]
DataSet<Tuple4<Integer, Byte, Integer, Double>
result =
input1.cross(input2)
// select and reorder fields of matching tuples
.projectSecond(0).projectFirst(1,0).projectSecond(1)
.types(Integer.class, Byte.class, Integer.class, Double.class);
The field selection in a Cross projection works the same way as in the projection of Join results.
Cross with DataSet Size Hint
In order to guide the optimizer to pick the right execution strategy, you can hint the size of a DataSet to cross as shown here:
DataSet<Tuple2<Integer, String>> input1 = // [...]
DataSet<Tuple2<Integer, String>> input2 = // [...]
DataSet<Tuple4<Integer, String, Integer, String>>
udfResult =
// hint that the second DataSet is very small
input1.crossWithTiny(input2)
// apply any Cross function (or projection)
.with(new MyCrosser());
DataSet<Tuple3<Integer, Integer, String>>
projectResult =
// hint that the second DataSet is very large
input1.crossWithHuge(input2)
// apply a projection (or any Cross function)
.projectFirst(0,1).projectSecond(1).types(Integer.class, String.class, String.class)
CoGroup
The CoGroup transformation jointly processes groups of two DataSets. Both DataSets are grouped on a defined key and groups of both DataSets that share the same key are handed together to a user-defined CoGroupFunction. If for a specific key only one DataSet has a group, the CoGroupFunction is called with this group and an empty group.
A CoGroupFunction can separately iterate over the elements of both groups and return an arbitrary number of result elements.
Similar to Reduce, GroupReduce, and Join, keys can be defined using
- a
KeySelectorfunction or - one or more field position keys (
TupleDataSetonly).
CoGroup on DataSets grouped by Field Position Keys (Tuple DataSets only)
// Some CoGroupFunction definition
class MyCoGrouper
extends CoGroupFunction<Tuple2<String, Integer>, Tuple2<String, Double>, Double> {
// set to hold unique Integer values
Set<Integer> ints = new HashSet<Integer>();
@Override
public void coGroup(Iterator<Tuple2<String, Integer>> iVals,
Iterator<Tuple2<String, Double>> dVals,
Collector<Double> out) {
// clear Integer set
ints.clear();
// add all Integer values in group to set
while(iVals.hasNext()) {
ints.add(iVals.next().f1);
}
// multiply each Double value with each unique Integer values of group
while(dVals.hasNext()) {
for(Integer i : ints) {
out.collect(dVals.next().f1 * i));
}
}
}
}
// [...]
DataSet<Tuple2<String, Integer>> iVals = // [...]
DataSet<Tuple2<String, Double>> dVals = // [...]
DataSet<Double> output = iVals.coGroup(dVals)
// group first DataSet on first tuple field
.where(0)
// group second DataSet on first tuple field
.equalTo(0)
// apply CoGroup function on each pair of groups
.with(new MyCoGrouper());
CoGroup on DataSets grouped by Key Selector Function
Works analogous to key selector functions in Join transformations.
Union
Produces the union of two DataSets, which have to be of the same type. A union of more than two DataSets can be implemented with multiple union calls, as shown here:
DataSet<Tuple2<String, Integer>> vals1 = // [...]
DataSet<Tuple2<String, Integer>> vals2 = // [...]
DataSet<Tuple2<String, Integer>> vals3 = // [...]
DataSet<Tuple2<String, Integer>> unioned = vals1.union(vals2)
.union(vals3);
Data Sources
Data sources create the initial data sets, such as from files or from Java collections. The general mechanism of of creating data sets is abstracted behind an InputFormat. Stratosphere comes with several built-in formats to create data sets from common file formats. Many of them have shortcut methods on the ExecutionEnvironment.
File-based:
readTextFile(path)/TextInputFormat- Reads files line wise and returns them as Strings.readTextFileWithValue(path)/TextValueInputFormat- Reads files line wise and returns them as StringValues. StringValues are mutable strings.readCsvFile(path)/CsvInputFormat- Parses files of comma (or another char) delimited fields. Returns a DataSet of tuples. Supports the basic java types and their Value counterparts as field types.
Collection-based:
fromCollection(Collection)- Creates a data set from the Java Java.util.Collection. All elements in the collection must be of the same type.fromCollection(Iterator, Class)- Creates a data set from an iterator. The class specifies the data type of the elements returned by the iterator.fromElements(T ...)- Creates a data set from the given sequence of objects. All objects must be of the same type.fromParallelCollection(SplittableIterator, Class)- Creates a data set from an iterator, in parallel. The class specifies the data type of the elements returned by the iterator.generateSequence(from, to)- Generates the squence of numbers in the given interval, in parallel.
Generic:
createInput(path)/InputFormat- Accepts a generic input format.
Examples
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// read text file from local files system
DataSet<String> localLines = env.readTextFile("file:///path/to/my/textfile");
// read text file from a HDFS running at nnHost:nnPort
DataSet<String> hdfsLines = env.readTextFile("hdfs://nnHost:nnPort/path/to/my/textfile");
// read a CSV file with three fields
DataSet<Tuple3<Integer, String, Double>> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.types(Integer.class, String.class, Double.class);
// read a CSV file with five fields, taking only two of them
DataSet<Tuple2<String, Double>> csvInput = env.readCsvFile("hdfs:///the/CSV/file")
.includeFields("10010") // take the first and the fourth fild
.types(String.class, Double.class);
// create a set from some given elements
DataSet<String> value = env.fromElements("Foo", "bar", "foobar", "fubar");
// generate a number sequence
DataSet<Long> numbers = env.generateSequence(1, 10000000);
// Read data from a relational database using the JDBC input format
DataSet<Tuple2<String, Integer> dbData =
env.createInput(
// create and configure input format
JDBCInputFormat.buildJDBCInputFormat()
.setDrivername("org.apache.derby.jdbc.EmbeddedDriver")
.setDBUrl("jdbc:derby:memory:persons")
.setQuery("select name, age from persons")
.finish(),
// specify type information for DataSet
new TupleTypeInfo(Tuple2.class, STRING_TYPE_INFO, INT_TYPE_INFO)
);
// Note: Stratosphere's program compiler needs to infer the data types of the data items which are returned by an InputFormat. If this information cannot be automatically inferred, it is necessary to manually provide the type information as shown in the examples above.
Data Sinks
Data sinks consume DataSets and are used to store or return them. Data sink operations are described using an OutputFormat. Stratosphere comes with a variety of built-in output formats that are encapsulated behind operations on the DataSet type:
writeAsText()/TextOuputFormat- Writes for each element as a String in a line. The String are obtained by calling the toString() method.writeAsCsv/CsvOutputFormat- Writes tuples as comma-separated value files. Row and field delimiters are configurable. The value for each field comes from the toString() method of the objects.print()/printToErr()- Prints the toString() value of each element on the standard out / strandard error stream.write()/FileOutputFormat- Method and base class for custom file outputs. Supports custom object-to-bytes conversion.output()/OutputFormat- Most generic output method, for data sinks that are not file based (such as storing the result in a database).
A DataSet can be input to multiple operations. Programs can write or print a data set and at the same time run additional transformations on them.
Examples
Standard data sink methods:
// text data
DataSet<String> textData = // [...]
// write DataSet to a file on the local file system
textData.writeAsText("file:///my/result/on/localFS");
// write DataSet to a file on a HDFS with a namenode running at nnHost:nnPort
textData.writeAsText("hdfs://nnHost:nnPort/my/result/on/localFS");
// write DataSet to a file and overwrite the file if it exists
textData.writeAsText("file:///my/result/on/localFS", WriteMode.OVERWRITE);
// tuples as lines with pipe as the separator "a|b|c"
DataSet<Tuple3<String, Integer, Double>> values = // [...]
values.writeAsCsv("file:///path/to/the/result/file", "\n", "|");
// this writes tuples in the text formatting "(a, b, c)", rather than as CSV lines
value.writeAsText("file:///path/to/the/result/file");
Using a custom output format:
DataSet<Tuple3<String, Integer, Double>> myResult = [...]
// write Tuple DataSet to a relational database
myResult.output(
// build and configure OutputFormat
JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername("org.apache.derby.jdbc.EmbeddedDriver")
.setDBUrl("jdbc:derby:memory:persons")
.setQuery("insert into persons (name, age, height) values (?,?,?)")
.finish()
);
Debugging
Before running a data analysis program on a large data set in a distributed cluster, it is a good idea to make sure that the implemented algorithm works as desired. Hence, implementing data analysis programs is usually an incremental process of checking results, debugging, and improving.
Stratosphere provides a few nice features to significantly ease the development process of data analysis programs by supporting local debugging from within an IDE, injection of test data, and collection of result data. This section give some hints how to ease the development of Stratosphere programs.
Local Execution Environment
A LocalEnvironment starts a Stratosphere system within the same JVM process it was created in. If you start the LocalEnvironement from an IDE, you can set breakpoint in your code and easily debug your program.
A LocalEnvironment is created and used as follows:
final ExecutionEnvironment env = ExecutionEnvironment.createLocalEnvironment();
DataSet<String> lines = env.readTextFile(pathToTextFile);
// build your program
env.execute();
Collection Data Sources and Sinks
Providing input for an analysis program and checking its output is cumbersome done by creating input files and reading output files. Stratosphere features special data sources and sinks which are backed by Java collections to ease testing. Once a program has been tested, the sources and sinks can be easily replaced by sources and sinks that read from / write to external data stores such as HDFS.
Collection data sources can be used as follows:
final ExecutionEnvironment env = ExecutionEnvironment.createLocalEnvironment();
// Create a DataSet from a list of elements
DataSet<Integer> myInts = env.fromElements(1, 2, 3, 4, 5);
// Create a DataSet from any Java collection
List<Tuple2<String, Integer>> data = ...
DataSet<Tuple2<String, Integer>> myTuples = env.fromCollection(data);
// Create a DataSet from an Iterator
Iterator<Long> longIt = ...
DataSet<Long> myLongs = env.fromCollection(longIt, Long.class);
Note: Currently, the collection data source requires that data types and iterators implement Serializable. Furthermore, collection data sources can not be executed in parallel (degree of parallelism = 1).
A collection data sink is specified as follows:
DataSet<Tuple2<String, Integer>> myResult = ...
List<Tuple2<String, Integer>> outData = new ArrayList<Tuple2<String, Integer>>();
myResult.output(new LocalCollectionOutputFormat(outData));
Note: Collection data sources will only work correctly, if the whole program is executed in the same JVM!
Iteration Operators
Iterations implement loops in Stratosphere programs. The iteration operators encapsulate a part of the program and execute it repeatedly, feeding back the result of one iteration (the partial solution) into the next iteration. There are two types of iterations in Stratosphere: BulkIteration and DeltaIteration.
This section provides quick examples on how to use both operators. Check out the Introduction to Iterations page for a more detailed introduction.
Bulk Iterations
To create a BulkIteration call the iterate(int) method of the DataSet the iteration should start at. This will return an IterativeDataSet, which can be transformed with the regular operators. The single argument to the iterate call specifies the maximum number of iterations.
To specify the end of an iteration call the closeWith(DataSet) method on the IterativeDataSet to specify which transformation should be fed back to the next iteration. You can optionally specify a termination criterion with closeWith(DataSet, DataSet), which evaluates the second DataSet and terminates the iteration, if this DataSet is empty. If no termination criterion is specified, the iteration terminates after the given maximum number iterations.
The following example iteratively estimates the number Pi. The goal is to count the number of random points, which fall into the unit circle. In each iteration, a random point is picked. If this point lies inside the unit circle, we increment the count. Pi is then estimated as the resulting count divided by the number of iterations multiplied by 4.
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// Create initial IterativeDataSet
IterativeDataSet<Integer> initial = env.fromElements(0).iterate(10000);
DataSet<Integer> iteration = initial.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer i) throws Exception {
double x = Math.random();
double y = Math.random();
return i + ((x * x + y * y < 1) ? 1 : 0);
}
});
// Iteratively transform the IterativeDataSet
DataSet<Integer> count = initial.closeWith(iteration);
count.map(new MapFunction<Integer, Double>() {
@Override
public Double map(Integer count) throws Exception {
return count / (double) 10000 * 4;
}
}).print();
env.execute("Iterative Pi Example");You can also check out the K-Means example, which uses a BulkIteration to cluster a set of unlabeled points.
Delta Iterations
Delta iterations exploit the fact that certain algorithms do not change every data point of the solution in each iteration.
In addition to the partial solution that is fed back (called workset) in every iteration, delta iterations maintain state across iterations (called solution set), which can be updated through deltas. The result of the iterative computation is the state after the last iteration. Please refer to the Introduction to Iterations for an overview of the basic principle of delta iterations.
Defining a DeltaIteration is similar to defining a BulkIteration. For delta iterations, two data sets form the input to each iteration (workset and solution set), and two data sets are produced as the result (new workset, solution set delta) in each iteration.
To create a DeltaIteration call the iterateDelta(DataSet, int, int) (or iterateDelta(DataSet, int, int[]) respectively). This method is called on the initial solution set. The arguments are the initial delta set, the maximum number of iterations and the key positions. The returned DeltaIteration object gives you access to the DataSets representing the workset and solution set via the methods iteration.getWorket() and iteration.getSolutionSet().
Below is an example for the syntax of a delta iteration
// read the initial data sets
DataSet<Tuple2<Long, Double>> initialSolutionSet = // [...]
DataSet<Tuple2<Long, Double>> initialDeltaSet = // [...]
int maxIterations = 100;
int keyPosition = 0;
DeltaIteration<Tuple2<Long, Double>, Tuple2<Long, Double>> iteration = initialSolutionSet
.iterateDelta(initialDeltaSet, maxIterations, keyPosition);
DataSet<Tuple2<Long, Double>> candidateUpdates = iteration.getWorkset()
.groupBy(1)
.reduceGroup(new ComputeCandidateChanges());
DataSet<Tuple2<Long, Double>> deltas = candidateUpdates
.join(iteration.getSolutionSet())
.where(0)
.equalTo(0)
.with(new CompareChangesToCurrent());
DataSet<Tuple2<Long, Double>> nextWorkset = deltas
.filter(new FilterByThreshold());
iteration.closeWith(deltas, nextWorkset)
.writeAsCsv(outputPath);
Semantic Annotations
Semantic Annotations give hints about the behavior of a function by telling the system which fields in the input are accessed and which are constant between input and output data of a function (copied but not modified). Semantic annotations are a powerful means to speed up execution, because they allow the system to reason about reusing sort orders or partitions across multiple operations. Using semantic annotations may eventually save the program from unnecessary data shuffling or unnecessary sorts.
Semantic annotations can be attached to functions through Java annotations, or passed as arguments when invoking a function on a DataSet. The following example illustrates that:
@ConstantFields("1")
public class DivideFirstbyTwo extends MapFunction<Tuple2<Integer, Integer>, Tuple2<Integer, Integer>> {
@Override
public Tuple2<Integer, Integer> map(Tuple2<Integer, Integer> value) {
value.f0 /= 2;
return value;
}
}
The following annotations are currently available:
@ConstantFields: Declares constant fields (forwarded/copied) for functions with a single input data set (Map, Reduce, Filter, ...).@ConstantFieldsFirst: Declares constant fields (forwarded/copied) for functions with a two input data sets (Join, CoGroup, ...), with respect to the first input data set.@ConstantFieldsSecond: Declares constant fields (forwarded/copied) for functions with a two input data sets (Join, CoGroup, ...), with respect to the first second data set.@ConstantFieldsExcept: Declares that all fields are constant, except for the specified fields. Applicable to functions with a single input data set.@ConstantFieldsFirstExcept: Declares that all fields of the first input are constant, except for the specified fields. Applicable to functions with a two input data sets.@ConstantFieldsSecondExcept: Declares that all fields of the second input are constant, except for the specified fields. Applicable to functions with a two input data sets.
(Note: The system currently evaluated annotations only on Tuple data types. This will be extended in the next versions)
Note: It is important to be conservative when providing annotations. Only annotate fields, when they are always constant for every call to the function. Otherwise the system has incorrect assumptions about the execution and the execution may produce wrong results. If the behavior of the operator is not clearly predictable, no annotation should be provided.
Broadcast Variables
Broadcast variables allow you to make a data set available to all parallel instances of an operation, in addition to the regular input of the operation. This is useful
for auxiliary data sets, or data-dependent parameterization. The data set will then be accessible at the operator as an Collection<T>.
- Broadcast: broadcast sets are registered by name via
withBroadcastSet(DataSet, String), and - Access: accessible via
getRuntimeContext().getBroadcastVariable(String)at the target operator.
// 1. The DataSet to be broadcasted
DataSet<Integer> toBroadcast = env.fromElements(1, 2, 3);
DataSet<String> data = env.fromElements("a", "b");
data.map(new MapFunction<String, String>() {
@Override
public void open(Configuration parameters) throws Exception {
// 3. Access the broadcasted DataSet as a Collection
Collection<Integer> broadcastSet = getRuntimeContext().getBroadcastVariable("broadcastSetName");
}
@Override
public String map(String value) throws Exception {
...
}
}).withBroadcastSet(toBroadcast, "broadcastSetName"); // 2. Broadcast the DataSet
Make sure that the names (broadcastSetName in the previous example) match when registering and accessing broadcasted data sets. For a complete example program, have a look at
KMeans Algorithm.
Note: As the content of broadcast variables is kept in-memory on each node, it should not become too large. For simpler things like scalar values you can simply make parameters part of the closure of a function, or use the withParameters(...) method to pass in a configuration.
Program Packaging & Distributed Execution
As described in the program skeleton section, Stratosphere programs can be executed on clusters by using the RemoteEnvironment. Alternatively, programs can be packaged into JAR Files (Java Archives) for execution. Packaging the program is a prerequisite to executing them through the command line interface or the web interface.
Packaging Programs
To support execution from a packaged JAR file via the command line or web interface, a program must use the environment obtained by ExecutionEnvironment.getExecutionEnvironment(). This environment will act as the cluster's environment when the JAR is submitted to the command line or web interface. If the Stratosphere program is invoked differently than through these interfaces, the environment will act like a local environment.
To package the program, simply export all involved classes as a JAR file. The JAR file's manifest must point to the class that contains the program's entry point (the class with the public void main(String[]) method). The simplest way to do this is by putting the main-class entry into the manifest (such as main-class: eu.stratosphere.example.MyProgram). The main-class attribute is the same one that is used by the Java Virtual Machine to find the main method when executing a JAR files through the command java -jar pathToTheJarFile. Most IDEs offer to include that attribute automatically when exporting JAR files.
Packaging Programs through Plans
Additionally, the Java API supports packaging programs as Plans. This method resembles the way that the Scala API packages programs. Instead of defining a progam in the main method and calling execute() on the environment, plan packaging returns the Program Plan, which is a description of the program's data flow. To do that, the program must implement the eu.stratosphere.api.common.Program interface, defining the getPlan(String...) method. The strings passed to that method are the command line arguments. The program's plan can be created from the environment via the ExecutionEnvironment#createProgramPlan() method. When packaging the program's plan, the JAR manifest must point to the class implementing the eu.stratosphere.api.common.Program interface, instead of the class with the main method.
Summary
The overall procedure to invoke a packaged program is as follows:
- The JAR's manifest is searched for a main-class or program-class attribute. If both attributes are found, the program-class attribute takes precedence over the main-class attribute. Both the command line and the web interface support a parameter to pass the entry point class name manually for cases where the JAR manifest contains neither attribute.
- If the entry point class implements the
eu.stratosphere.api.common.Program, then the system calls thegetPlan(String...)method to obtain the program plan to execute. ThegetPlan(String...)method was the only possible way of defining a program in the Record API (see 0.4 docs) and is also supported in the new Java API. - If the entry point class does not implement the
eu.stratosphere.api.common.Programinterface, the system will invoke the main method of the class.
Accumulators & Counters
Accumulators are simple constructs with an add operation and a final accumulated result, which is available after the job ended.
The most straightforward accumulator is a counter: You can increment it using the Accumulator.add(V value) method. At the end of the job Stratosphere will sum up (merge) all partial results and send the result to the client. Since accumulators are very easy to use, they can be useful during debugging or if you quickly want to find out more about your data.
Stratosphere currently has the following built-in accumulators. Each of them implements the Accumulator interface.
- IntCounter, LongCounter and DoubleCounter: See below for an example using a counter.
- Histogram: A histogram implementation for a discrete number of bins. Internally it is just a map from Integer to Integer. You can use this to compute distributions of values, e.g. the distribution of words-per-line for a word count program.
How to use accumulators:
First you have to create an accumulator object (here a counter) in the operator function where you want to use it. Operator function here refers to the (anonymous inner) class implementing the user defined code for an operator.
private IntCounter numLines = new IntCounter();
Second you have to register the accumulator object, typically in the open() method of the operator function. Here you also define the name.
getRuntimeContext().addAccumulator("num-lines", this.numLines);
You can now use the accumulator anywhere in the operator function, including in the open() and close() methods.
this.numLines.add(1);
The overall result will be stored in the JobExecutionResult object which is returned when running a job using the Java API (currently this only works if the execution waits for the completion of the job).
myJobExecutionResult.getAccumulatorResult("num-lines")
All accumulators share a single namespace per job. Thus you can use the same accumulator in different operator functions of your job. Stratosphere will internally merge all accumulators with the same name.
A note on accumulators and iterations: Currently the result of accumulators is only available after the overall job ended. We plan to also make the result of the previous iteration available in the next iteration. You can use Aggregators to compute per-iteration statistics and base the termination of iterations on such statistics.
Custom accumulators:
To implement your own accumulator you simply have to write your implementation of the Accumulator interface. Feel free to create a pull request if you think your custom accumulator should be shipped with Stratosphere.
You have the choice to implement either Accumulator or SimpleAccumulator. Accumulator<V,R> is most flexible: It defines a type V for the value to add, and a result type R for the final result. E.g. for a histogram, V is a number and R is a histogram. SimpleAccumulator is for the cases where both types are the same, e.g. for counters.
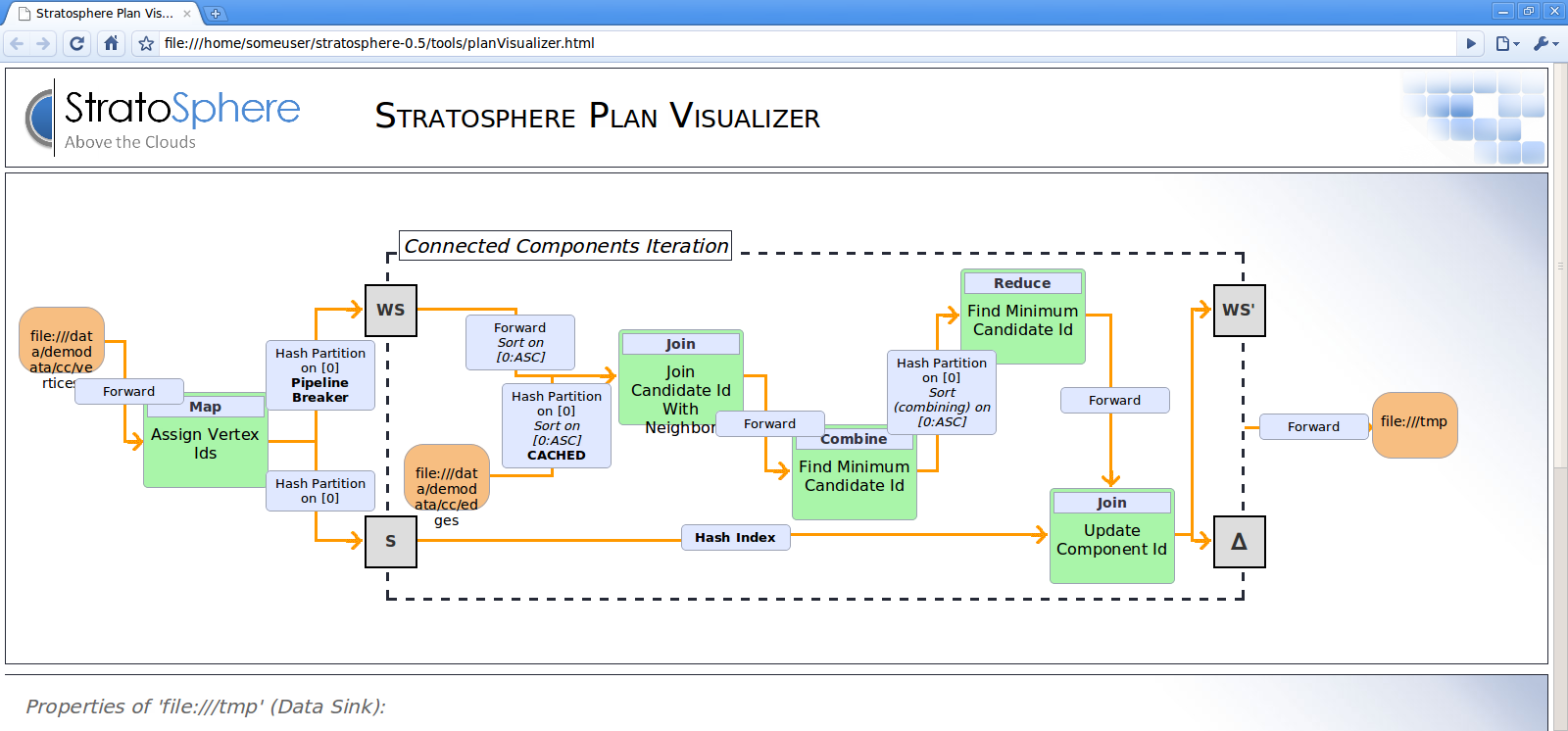
Execution Plans
Depending on various parameters such as data size or number of machines in the cluster, Stratosphere's optimizer automatically chooses an execution strategy for your program. In many cases, it can be useful to know how exactly Stratosphere will execute your program.
Plan Visualization Tool
Stratosphere 0.5 comes packaged with a visualization tool for execution plans. The HTML document containing the visualizer is located under tools/planVisualizer.html. It takes a JSON representation of the job execution plan and visualizes it as a graph with complete annotations of execution strategies.
The following code shows how to print the execution plan JSON from your program:
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
...
System.out.println(env.getExecutionPlan());
To visualize the execution plan, do the following:
- Open
planVisualizer.htmlwith your web browser, - Paste the JSON string into the text field, and
- Press the draw button.
After these steps, a detailed execution plan will be visualized.
 Web Interface
Web Interface
Stratosphere offers a web interface for submitting and executing jobs. If you choose to use this interface to submit your packaged program, you have the option to also see the plan visualization.
The script to start the webinterface is located under bin/start-webclient.sh. After starting the webclient (per default on port 8080), your program can be uploaded and will be added to the list of available programs on the left side of the interface.
You are able to specify program arguments in the textbox at the bottom of the page. Checking the plan visualization checkbox shows the execution plan before executing the actual program.
comments powered by DisqusApache Flink is an effort undergoing incubation at The Apache Software Foundation (ASF), sponsored by the Apache Incubator PMC. Incubation is required of all newly accepted projects until a further review indicates that the infrastructure, communications, and decision making process have stabilized in a manner consistent with other successful ASF projects. While incubation status is not necessarily a reflection of the completeness or stability of the code, it does indicate that the project has yet to be fully endorsed by the ASF.
![]()