We are pleased to announce that version 0.4 of the Stratosphere system has been released.
Our team has been working hard during the last few months to create an improved and stable Stratosphere version. The new version comes with many new features, usability and performance improvements in all levels, including a new Scala API for the concise specification of programs, a Pregel-like API, support for Yarn clusters, and major performance improvements. The system features now first-class support for iterative programs and thus covers traditional analytical use cases as well as data mining and graph processing use cases with great performance.
In the course of the transition from v0.2 to v0.4 of the system, we have changed pre-existing APIs based on valuable user feedback. This means that, in the interest of easier programming, we have broken backwards compatibility and existing jobs must be adapted, as described in the migration guide.
This article will guide you through the feature list of the new release.
Scala Programming Interface
The new Stratosphere version comes with a new programming API in Scala that supports very fluent and efficient programs that can be expressed with very few lines of code. The API uses Scala's native type system (no special boxed data types) and supports grouping and joining on types beyond key/value pairs. We use code analysis and code generation to transform Scala's data model to the Stratosphere runtime. Stratosphere Scala programs are optimized before execution by Stratosphere's optimizer just like Stratosphere Java programs.
Learn more about the Scala API at the Scala Programming Guide
Iterations
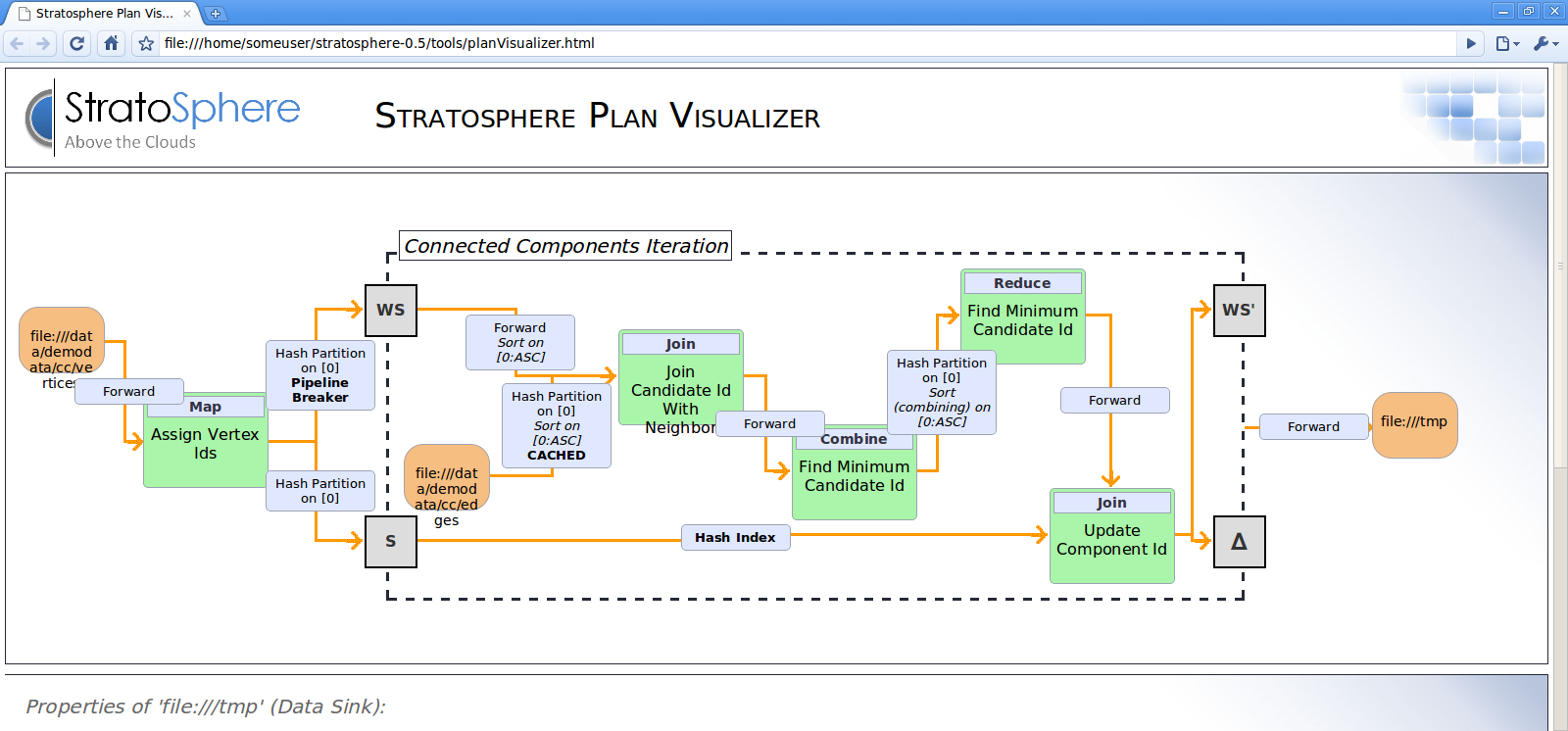
Stratosphere v0.4 introduces deep support for iterative algorithms, required by a large class of advanced analysis algorithms. In contrast to most other systems, "looping over the data" is done inside the system's runtime, rather than in the client. Individual iterations (supersteps) can be as fast as sub-second times. Loop-invariant data is automatically cached in memory.
We support a special form of iterations called “delta iterations” that selectively modify only some elements of intermediate solution in each iteration. These are applicable to a variety of applications, e.g., use cases of Apache Giraph. We have observed speedups of 70x when using delta iterations instead of regular iterations.
Read more about the new iteration feature in the documentation
Hadoop YARN Support
YARN (Yet Another Resource Negotiator) is the major new feature of the recently announced Hadoop 2.2. It allows to share existing clusters with different runtimes. So you can run MapReduce alongside Storm and others. With the 0.4 release, Stratosphere supports YARN.
Follow our guide on how to start a Stratosphere YARN session.
Improved Scripting Language Meteor
The high-level language Meteor now natively serializes JSON trees for greater performance and offers additional operators and file formats. We greatly empowered the user to write crispier scripts by adding second-order functions, multi-output operators, and other syntactical sugar. For developers of Meteor packages, the API is much more comprehensive and allows to define custom data types that can be easily embedded in JSON trees through ad-hoc byte code generation.
Spargel: Pregel Inspired Graph Processing
Spargel is a vertex-centric API similar to the interface proposed in Google's Pregel paper and implemented in Apache Giraph. Spargel is implemented in 500 lines of code (including comments) on top of Stratosphere's delta iterations feature. This confirms the flexibility of Stratosphere's architecture.
Web Frontend
Using the new web frontend, you can monitor the progress of Stratosphere jobs. For finished jobs, the frontend shows a breakdown of the execution times for each operator. The webclient also visualizes the execution strategies chosen by the optimizer.
Accumulators
Stratosphere's accumulators allow program developers to compute simple statistics, such as counts, sums, min/max values, or histograms, as a side effect of the processing functions. An example application would be to count the total number of records/tuples processed by a function. Stratosphere will not launch additional tasks (reducers), but will compute the number "on the fly" as a side-product of the functions application to the data. The concept is similar to Hadoop's counters, but supports more types of aggregation.
Refactored APIs
Based on valuable user feedback, we refactored the Java programming interface to make it more intuitive and easier to use. The basic concepts are still the same, however the naming of most interfaces changed and the structure of the code was adapted. When updating to the 0.4 release you will need to adapt your jobs and dependencies. A previous blog post has a guide to the necessary changes to adapt programs to Stratosphere 0.4.
Local Debugging
You can now test and debug Stratosphere jobs locally. The LocalExecutor allows to execute Stratosphere Jobs from IDE's. The same code that runs on clusters also runs in a single JVM multi-threaded. The mode supports full debugging capabilities known from regular applications (placing breakpoints and stepping through the program's functions). An advanced mode supports simulating fully distributed operation locally.
Miscellaneous
- The configuration of Stratosphere has been changed to YAML
- HBase support
- JDBC Input format
- Improved Windows Compatibility: Batch-files to start Stratosphere on Windows and all unit tests passing on Windows.
- Stratosphere is available in Maven Central and Sonatype Snapshot Repository
- Improved build system that supports different Hadoop versions using Maven profiles
- Maven Archetypes for Stratosphere Jobs.
- Stability and Usability improvements with many bug fixes.
Download and get started with Stratosphere v0.4
There are several options for getting started with Stratosphere.
Tell us what you think!
Are you using, or planning to use Stratosphere? Sign up in our mailing list and drop us a line.
Have you found a bug? Post an issue on GitHub.
Follow us on Twitter and GitHub to stay in touch with the latest news!