Java API
Stratosphere programs are parallel data flows that transform and combine data sets using a series of operations.
In a nutshell a program consists of one or more data sources that produce the data (for example by reading it from a file), the transforming operations, and one or more data sinks that take the program’s result (for example writing it to a file or printing it). The sources, sinks, and operations together form the plan, which is submitted to the system for execution. You can think of MapReduce as a special case of such a program, which has exactly two operations: Map and Reduce.
Classes from this API are found in eu.stratosphere.api.java.record. In addition, it uses some generic API classes from eu.stratosphere.api.common. Note that we refer to this API as the Java Record API to differentiate it from the new Java API that is currently under development.
Overview
| Sources | Operations | Sinks |
|---|---|---|
|
|
|
These building blocks could result in the following Stratosphere program, which shows two input sources, map, reduce, and join operations, and a single sink:
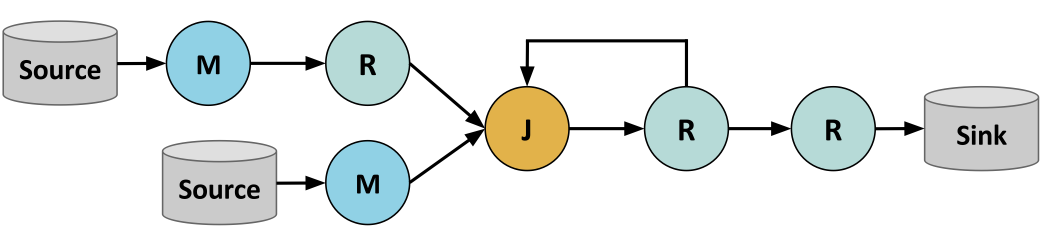
Linking with Stratosphere
To write programs with Stratosphere, you need to include Stratosphere’s Java API library in your project.
The simplest way to do this is to use the quickstart scripts. They create a blank project from a Maven Archetype (think of it as a template), which sets up everything for you. To manually create the project, you can use the archetype and create a project by calling:
mvn archetype:generate /
-DarchetypeGroupId=eu.stratosphere /
-DarchetypeArtifactId=quickstart-java /
-DarchetypeVersion=0.4
If you want to add Stratosphere to an existing Maven project, add the following entry to your dependencies in the pom.xml file of your project:
<dependency>
<groupId>eu.stratosphere</groupId>
<artifactId>stratosphere-java</artifactId>
<version>0.4</version>
</dependency>
<dependency>
<groupId>eu.stratosphere</groupId>
<artifactId>stratosphere-clients</artifactId>
<version>0.4</version>
</dependency>
The second dependency is only necessary for a local execution context. You only need to include it, if you want to execute Stratosphere programs on your local machine (for example for testing or debugging).
Program Skeleton
The following is a typical skeleton of a program in Stratosphere’s Java API. It creates a data source for a file and a data sink for the result, and returns a plan.
public class Skeleton implements Program {
@Override
public Plan getPlan(String... args) {
FileDataSource source = new FileDataSource(new TextInputFormat(), "file:///path/to/input");
// Operations on the data set go here
// ...
FileDataSink sink = new FileDataSink(new CsvOutputFormat(), "file:///path/to/result");
return new Plan(sink);
}
}
Note that the plan references only to the sink. The transformations and sources are gathered by following the plan back from the sinks. This implies that any transformation that is not used in a sink is omitted.
Records
All data sets are collections of records. These records are produced by data sources and transformed by the operations. The records (eu.stratosphere.types.Record) can be thought of as dynamically typed tuples. Fields are accessed by position (starting from zero) and type, as shown in the example below.
Record r = ...
IntValue val = r.getField(3, IntValue.class);
r.setField(5, new StringValue("some text"));
The types can be Stratosphere’s base types, or any custom type that implements the Value interface (eu.stratosphere.types.Value). If a field is used as a key (for example in a grouping or a join), it must implement the Key interface as well (eu.stratosphere.types.Key).
The record typically deserializes the fields as they are accessed. For performance reasons, the record internally caches the objects of the fields that are accessed. Hence, accessing the same field multiple times returns the same object.
The record may be sparse, i.e., you can for example set only the fields 2 and 5 and leave the other fields empty. The unset fields before the largest fields are implicitly set to null.
Operations
The operations applied on the data sets to transform them form the core of a Stratosphere program. The data sets are collections of records, and each operation is a function that is applied to the records to transform them. The table below lists the available operations:
| Operator | Description |
|---|---|
| Map |
Transforms each record individually. The operation may return zero, one, or many records. |
| Reduce |
Groups the records on one or more fields and transforms each group. Typical examples are aggregations that combine the records in the group into a single record. This reduce operator groups on the 0th field of type StringValue. You can add further key fields with the If you annotate your class with the |
| CoGroup |
The two-dimensional variant of the reduce operation. Groups each input on one or more fields and then joins the groups. The transformation function is called per pair of groups. This join operator groups on field 0 of source1 and field 1 of source2, both of which are of type IntValue. You can add further key fields with the |
| Join |
Joins two data sets on one or more fields. The transformation function gets each pair of joining records. This join operator groups on field 0 of source1 and field 1 of source2, both of which are of type IntValue. You can add further key fields with the |
| Cross |
Builds the cartesian product (cross product) of two inputs. The transformation function gets all pairs of records in the product. If you expect the first input to be large and the second small, use the
|
| Union |
Produces the union of two data sets. This operation happens implicitly if more than one data set is used for a specific function input. In the same fashion, you can also provide multiple inputs to the other operators. |
Input/Output Formats
Data sets are created and returned through data sources and sinks. These sources and sinks execute input and output formats, which describe how records are created and consumed. For example they implement file parsing, or database query logic. The following is a list of the most commonly used input and output formats that are included:
| Input Format | Description |
|---|---|
| TextInputFormat | Reads a text file line wise and returns a record with one field, which is the string for the line. |
| CsvInputFormat | Reads a sequence of comma (or another character) delimited values. Needs to be parameterized with the expected field types and returns records with a field for each field In the CSV file. Record and field delimiters are customizable. |
| DelimitedInputFormat | Base class for input formats that parse a file into byte records using a record delimiter. Requires to implement the method that transforms the bytes into a record. |
| FileInputFormat | Base class of all input formats that read from files. Can be extended for custom file formats. |
| JDBCInputFormat | Issues a database query and returns the result cursor as a record stream. |
| Output Format | Description |
|---|---|
| CsvOutputFormat | Writes the records a sequence of comma (or another character) delimited values. Needs to be parameterized with the types of the record. |
| DelimitedOutputFormat | Base class for output formats that write results as a sequence of delimited records, for example as lines. Requires to implement the method that turns the record into a byte sequence. |
| FileOutputFormat | Base class of all output formats that write to files. Can be extended for custom file formats. |
You can implement your own arbitrary format as extensions of eu.stratosphere.api.common.io.InputFormat and eu.stratosphere.api.common.io.OutputFormat.
Iterations
Iterations allow you to implement loops in Stratosphere programs. This page gives a general introduction to iterations. This section here provides quick examples. The iteration operators encapsulate a part of the program and execute it repeatedly, feeding back the result of one iteration (the partial solution) into the next iteration. Stratosphere has two different types of iterations, BulkIteration and DeltaIteration.
Bulk Iterations
For BulkIterations, programs instantiate the BulkIteration operator and then simply define the operations to be executed iteratively, referring to the iteration operator for the input. The example below illustrates this:
FileDataSource pageWithRankInput = new FileDataSource(...);
BulkIteration iteration = new BulkIteration("Page Rank Loop");
iteration.setInput(pageWithRankInput);
// from here on is the iterative function
FileDataSource links = new FileDataSource(...);
JoinOperator join = JoinOperator.builder(new JoinVerexWithEdgesJoin(), LongValue.class, 0, 0)
.input1(iteration.getPartialSolution()) // take the iterative result as the input
.input2(links)
.build();
ReduceOperator rankAggregation = ReduceOperator.builder(new AggregatingReduce(), LongValue.class, 0)
.input(join)
.build();
iteration.setNextPartialSolution(rankAggregation);
iteration.setMaximumNumberOfIterations(numIterations);
FileDataSink result = new FileDataSink(...);
result.setInput(iteration); // the result of the iteration
Bulk iterations terminate after a given number of iterations, or after a termination criterion. Currently, this termination criterion can only be specified using the aggregators (eu.stratosphere.api.common.aggregators).
Delta Iterations
Delta iterations exploit the fact that many algorithms do not change every record in the solution in each iteration. In addition to the partial solution data set that is fed back (here called the workset), delta iterations maintain a state across iterations (solution set), which can be joined with and which is updated through deltas. The result of the iterative computation is the state after the last iteration. Please see this page for an introduction to the basic principle of delta iterations.
Defining delta iterations is similar to defining a bulk iteration. For delta iterations, two data sets form the input to each iteration (workset and solution set), and two data sets are produced as the result (new workset, solution set delta). In addition, the elements in the workset must be uniquely defined through a key. That key is used to replace elements in the solution set with elements from the delta. The code below shows this in an example:
DeltaIteration iteration = new DeltaIteration(1); // field 1 is the solution set key
iteration.setInitialSolutionSet(...);
iteration.setInitialWorkset(...);
// join workset and solution set (it is possible to apply other operation on the workset before)
JoinOperator join = JoinOperator.builder(new MyWorksetJoin(), LongValue.class, 0, 1)
.input1(iteration.getWorkset())
.input2(iteration.getSolutionSet())
.build();
ReduceOperator min = ReduceOperator.builder(new Minimum(), LongValue.class, 1)
.input(join).build();
iteration.setSolutionSetDelta(min); // define the solution set delta
MapOperator filtered = MapOperator.builder(new ThresholdFilter())
.input(min).build();
iteration.setNextWorkset(filtered); // define workset for next iteration
FileDataSink result = new FileDataSink(new CsvOutputFormat(), "file:///result", iteration);
Accumulators and Counters
Accumulators are simple constructs with an add operation and a final (accumulated) result, which is available after the job ended. The most straightforward accumulator is a counter: You can increment it, using the Accumulator.add(V value) method, and at the end of the job Stratosphere will sum up (merge) all partial results and send the result to the client. Since accumulators are very easy to use, they can be useful during debugging or if you quickly want to find out more about your data.
Stratosphere currently has the following built-in accumulators. Each of them implements the Accumulator interface.
- IntCounter, LongCounter and DoubleCounter: See below for an example using a counter.
- Histogram: A histogram implementation for a discrete number of bins. Internally it is just a map from Integer to Integer. You can use this to compute distributions of values, e.g. the distribution of words-per-line for a word count program.
How to use accumulators:
First you have to create an accumulator object (here a counter) in the stub where you want to use it.
private IntCounter numLines = new IntCounter();
Second you have to register the accumulator object, typically in the open() method of the stub. Here you also define the name.
getRuntimeContext().addAccumulator("num-lines", this.numLines);
You can now use the accumulator anywhere in the stub, including in the open() and close() methods.
this.numLines.add(1);
The overall result will be stored in the JobExecutionResult object which is returned when running a job using the Java API (currently this only works if the execution waits for the completion of the job).
myJobExecutionResult.getAccumulatorResult("num-lines")
All accumulators share a single namespace per job. Thus you can use the same accumulator in different stubs of your job. Stratosphere will internally merge all accumulators with the same name.
Please look at the WordCountAccumulator example for a complete example.
A note on accumulators and iterations: Currently the result of accumulators is only available after the overall job ended. We plan to make the result of the previous iteration available in the next iteration.
Custom accumulators:
To implement your own accumulator you simply have to write your implementation of the Accumulator interface. Please look at the WordCountAccumulator example for an example. Feel free to create a pull request if you think your custom accumulator should be shipped with Stratosphere.
You have the choice to implement either Accumulator or SimpleAccumulator. Accumulator<V,R> is most flexible: It defines a type V for the value to add, and a result type R for the final result. E.g. for a histogram, V is a number and R is a histogram. SimpleAccumulator is for the cases where both types are the same, e.g. for counters.
Configuration
All functions provide open(Configuration) and close() methods, which are called when the respective function instance (e.g. MapFunction) is opened and closed.
This allows to instantiate data structures to be used across user-defined functions calls. It also improves the re-usability of function implementations as functions can be parametrized, e.g. to have configurable filter values instead of hard-coding them into the function implementation.
Stratosphere calls open(Configuration) with a Configuration object that holds all parameters which were passed to the function. To set parameters, you can use the following methods at the driver:
- setParameter(String key, int value),
- setParameter(String key, String value), or
- setParameter(String key, boolean value).
// --- program assembly ---
public class Skeleton implements Program {
@Override
public Plan getPlan(String... args) {
...
MapOperator mapper = MapOperator.builder(new MyMapper())
.input(source)
.name("MyMapper")
.build();
// configuration parameters
mapper.setParameter("param.year", 2014);
mapper.setParameter("param.name", "Stratosphere");
...
return plan;
}
}
// --- map function ---
public class MyMapper extends MapFunction {
private int year;
private String name;
public void open(Configuration config) {
this.year = config.getInteger("param.year", 0);
this.name = config.getString("param.name", "");
}
public void map(Record record, Collector<Record> out) {
out.collect(...);
}
}
This code excerpt has been adapted from the TPCHQuery3 example program, where the parameters are used to set filtering and join parameters.