Example Programs
The following example programs showcase different applications of Stratosphere from graph processing to data mining problems and relational queries.
The examples consist of a task description and an in-depth discussion of the solving program. Sample data for the jobs is either provided by data set generators or links to external data sets or data set generators. The source code of all example jobs can be found in the pact-example module (https://github.com/stratosphere/stratosphere/blob/master/pact/pact-examples/src/main/java/eu/stratosphere/pact/example).
Please note: The goal of the programs is to assist you in understanding the programming model. Hence, the code often written in a more understandable way rather than in the most efficient way. If you want to learn how to write efficient and fast PACT programs, have a look at advanced PACT programming.
Overview:
- Classic MapReduce
- Relational Queries
- Data Mining
- Graph Analysis Algorithms
Word Count
Counting words is the classic example to introduce parallelized data processing with MapReduce. It demonstrates how the frequencies of words in a document collection are computed.
The source code of this example can be found here.
Algorithm Description
The WordCount algorithm works as follows:
- The text input data is read line by line
- Each line is cleansed (removal of non-word characters, conversion to lower case, etc.) and tokenized by words.
- Each word is paired with a partial count of “1”.
- All pairs are grouped by the word and the total group count is computed by summing up partial counts.
A detailed description of the implementation of the WordCount algorithm for Hadoop MapReduce can be found at Hadoop's Map/Reduce Tutorial.
PACT Program
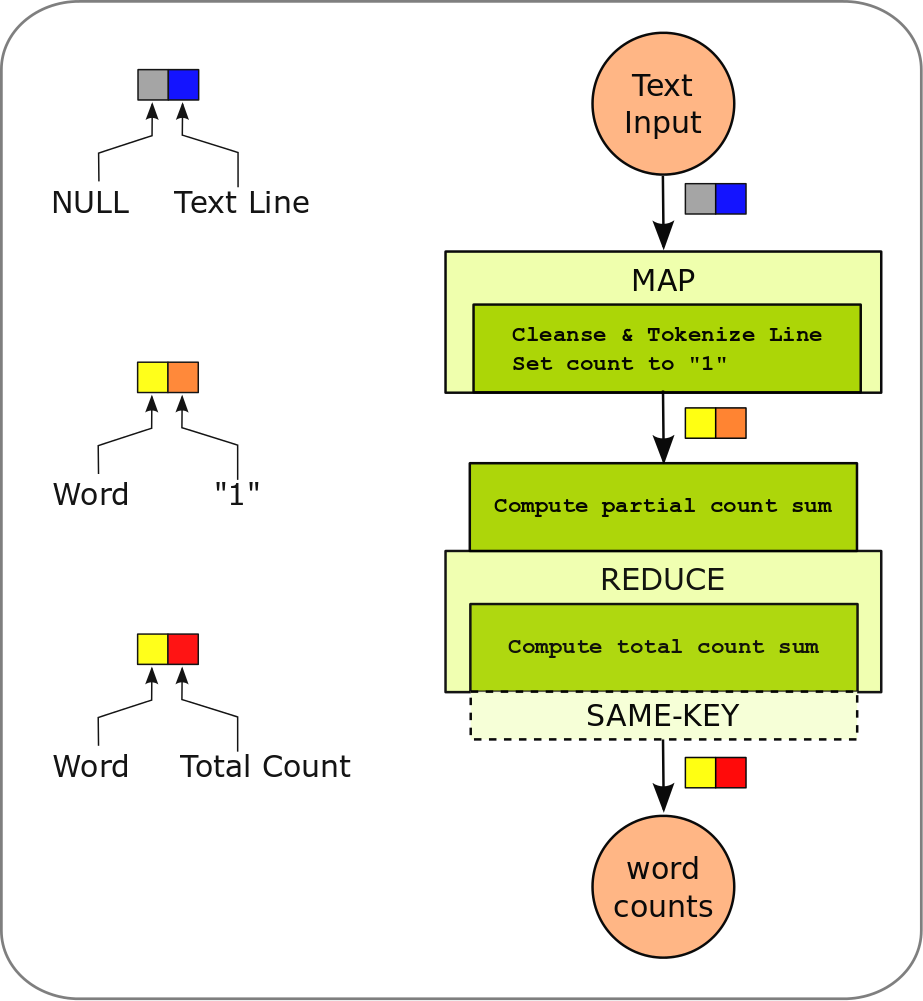
The example PACT program implements the above described algorithm.
- The PACT program starts with an input data source. The
DataSourceContract produces a list of key-value pairs. Each line of
the input file becomes a value. The key is not used here and hence
set to
NULL. - The Map PACT is used to split each line into single words. The user
code tokenizes the line by whitespaces (
'','\t', …) into single words. Each word is emitted in an independent key-value pair, where the key is the word itself and the value is an Integer “1”. - The Reduce PACT implements the reduce and combine methods. The
ReduceStub is annotated with
@Combinableto use the combine method. The combine method computes partial sums over the “1”-values emitted by the Map contract, the reduce method sums these partial sums and obtains the final count for each word. - The final DataSink contract writes the results back.
Program Arguments
Three arguments must be provided to the getPlan() method of the
example job:
-
int noSubStasks: Degree of parallelism of all tasks. -
String inputPath: Path to the input data. -
String outputPath: Destination path for the result.
Test Data
Any plain text file can be used as input for the the WordCount example. If you do not have a text file at hand, you can download some literature from the Gutenberg Project. For example
wget -O ~/hamlet.txt http://www.gutenberg.org/cache/epub/1787/pg1787.txt
will download Hamlet and put the text into a file called hamlet.txt in your home directory.
TPCH - Query 3
The source code of this example can be found here.
Task Description
The TPC-H benchmark is a decision support benchmark on relational data (see http://www.tpc.org/tpch/). The example below shows a PACT program realizing a modified version of Query 3 from TPC-H including one join, some filtering and an aggregation. The original query contains another join with the Customer relation, which we omitted to reduce the size of the example. The picture below shows the schema of the data to be analyzed and the corresponding SQL query.

PACT Program
The example PACT program implements the SQL Query given above in the Java class eu.stratosphere.pact.example.relational.TPCHQuery3 in the pact-examples module.
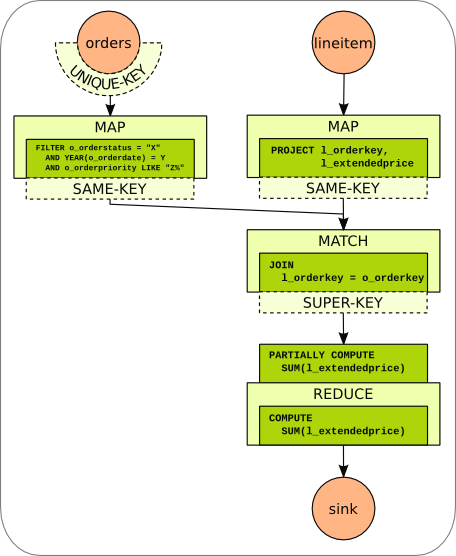
- The program starts with two data sources, one for the Orders relation and one for the Lineitem relation. The input format for both data sources uses the first attribute as key. For orders the first attribute is the primary key of the relation. Therefore, the key of each key/value-pair is unique and a !UniqueKey Output Contract is attached to the orders data source.
- Each data source is followed by a Map contract:
- Orders: Filtering and projection is done for the orders table in the map step. Since the key is not changed, a !SameKey Output Contract is attached.
- LineItem: Columns that are not needed are projected out in the map step. Since this map step does not alter the key,a !SameKey Output Contract is attached.
- The join is realized in a Match contract. The join condition (i.e., equality of orderkey attributes) is ensured by Match. Hence, the user code only concatenates the attributes of both tuples and builds a new key by concatenating orderkey and shippriority. The new key is a super key of the input key. Therefore, a !SuperKey Output Contract is attached.
- The Reduce step realizes the grouping by orderkey and shippriority and calculates the sum on the extended price. Partial sums are calculated in the combine step.
- The result is written back to a data sink.
Program Arguments
For this example job, four arguments must be provided to the getPlan()
method. Namely:
-
int noSubStasks: Degree of parallelism for all tasks. -
String orders: Path to the Orders relation. -
String lineitem: Path to the Lineitem relation. -
String outputPath: Destination path for the result output.
See !ExecutePactProgram or details on how to specify paths for Nephele.
Data Generation
The TPC-H benchmark suite provides a data generator tool (DBGEN) for generating sample input data (see http://www.tpc.org/tpch/). To use it together with PACT, take the following steps:
- Download and unpack DBGEN
- Make a copy of makefile.suite called Makefile and perform the following changes:
# PACT program was tested with DB2 data format
DATABASE = DB2
MACHINE = LINUX
WORKLOAD = TPCH
# according to your compiler, mostly gcc
CC = gcc
- Build DBGEN using make
- Generate lineitem and orders relations using dbgen. A scale factor (-s) of 1 results in a generated data set with about 1 GB size.
./dbgen -T o -s 1
Weblog Analysis
Task Description
The Weblog Analysis example shows how analyzing relational data can be done with the help of the PACT Programming Model.
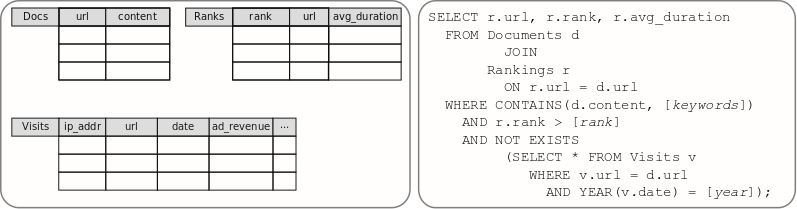
In this case a scenario is considered where the log files for different webpages are analyzed. These log files contain information about the page ranks and the page visits of the different webpages. The picture below gives the schema of the the data to be analyzed and the corresponding SQL query. The data is split into three relations:
- Docs (URL, content)
- Ranks (rank, URL, average duration)
- Visits (IP address, URL, date, advertising revenue, …)
The analysis task computes the ranking information of all documents that contain a certain set of keywords, have at least a certain rank, and have not been visited in a certain year.
PACT Program
The weblog analysis example PACT program is implemented in the following Java class: eu.stratosphere.pact.example.relational.WebLogAnalysis.java in the pact-examples module.
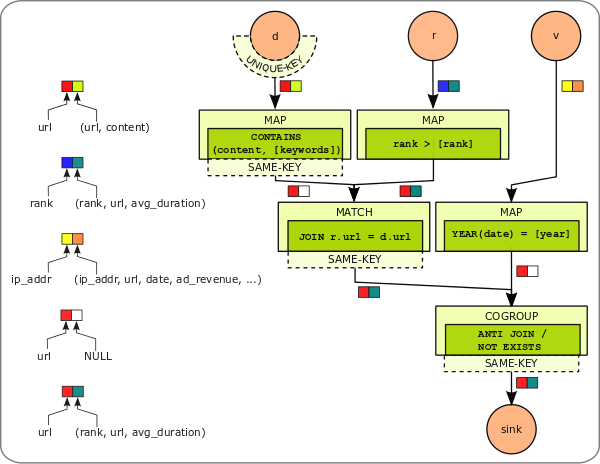
- Each relation is read by a separate DataSource contract. Each line is converted into a key-value-pair.
- The local predicates on each relation are applied by a Map contract.
- The Match contract performs the equality join between the docs and ranks relations.
- The anti join between the (docs JOIN ranks) and visits relations is performed by the CoGroup contract. Tuples of the ranks relation are forwarded if no tuple of the visits relation has the same key (url).
- The result is written by the final DataSink contract.
Program Arguments
Five arguments must be provided to the getPlan() method of the example job:
-
int noSubStasks: Degree of parallelism for all tasks. -
String docs: Path to the docs relation. -
String ranks: Path to the ranks relation. -
String visits: Path to the visits relation. -
String outputPath: Destination path for the result.
Data Generator
There are two generators which can provide data for the web-log analysis PACT example.
- A stand-alone generator for smaller data sets.
- A distributed generator for larger data sets.
Both generators produce identically structured test data.
Stand-Alone Generator
We provide a data set generator to generate the docs, ranks, and visits relations. The generator is implemented as Java class eu.stratosphere.pact.example.relational.generator.WebLogGenerator.java in the pact-examples module.
The parameters of the main method of the generator are:
- noDocuments: Number of generated doc and rank records.
- noVisits: Number of generated visit records.
- outPath: Path the where generated files are written.
- noFiles: Number of files into which all relations are split.
The data generated by our stand-alone generator follows only the schema of the distributed generator. Attribute values, distributions, and correlations are not the same.
Please consult the in-line JavaDocs for further information on the generator.
Distributed Generator
For generating larger data sets in a distributed environment, you can use a generator provided by Brown University (see Section Analysis Benchmarks Data Sets).
K-Means Iteration
The source code of this example can be found here.
Task description
The k-means cluster algorithm is a well-known algorithm to group data points in to clusters of similar points. In contrast to hierarchical cluster algorithms, the number of cluster centers has to be provided to the algorithm before it is started. K-means is an iterative algorithm, which means that certain steps are repeatably performed until a termination criterion is fulfilled.
The algorithm operates in five steps (see figure below):
- Starting point: A set of data points which shall be clustered is provided. A data point is a vector of features. A set of initial cluster centers is required as well. Cluster centers are feature vectors as well. The initial centers are randomly generated, fixed, or randomly picked from the set of data points. Finally, a distance metric that computes the distance between a data point and a cluster center is required.
- Compute Distances: An iteration starts with computing the distances of all data points to all cluster centers.
- Find Nearest Cluster: Each data point is assigned to the cluster center to which it is closest according to the computed distance.
- Recompute Center Positions: Each cluster center is moved to the center of all data points which were assigned to it.
- Check Termination Criterion: There are multiple different termination criteria such as a fixed number of iterations, a limit on the average distance the cluster centers have moved, or a combination of both. If the termination criteria was met, the algorithm terminates. Otherwise, it goes back to step 2 and uses the new cluster centers as input.

A detailed discussion of the K-Means clustering algorithm can be found here: http://en.wikipedia.org/wiki/K-means_clustering
PACT Program
The example PACT program implements one iteration step (steps 2,3, and 4) of the k-means algorithm. The implementation resides in the following Java class: eu.stratosphere.pact.example.kmeans.KMeansSingleStep.java in the pact-examples module. All required classes (data types, data formats, PACT stubs, etc.) are contained in this class as static inline classes.
The PACT program that implements the k-means iteration is shown in the figure below. The implementation follows the same steps as presented above. We discuss the program top-down in “flow direction” of the data.
- It starts at two data sources (!DataPoints and ClusterCenters) at
the top. Both sources produce key-value pairs from their input files
(stored in HDFS) where the ID is the key and the coordinates of the
data point or cluster center is the value.
Since it is assumed, that IDs are unique in both files, both data
sources are annotated with UniqueKey OutputContracts.
A Cross PACT is used to compute the distances of all data points to all cluster centers. The user code (highlighted as leaf green box) implements the distance computation of a single data point to a single cluster center. The Cross PACT takes care of enumerating all combinations of data points and cluster centers and calls the user code with each combination. The user code emits key-value pairs where the ID of the data point is the key (hence the
SameKeyLeftOutputContract is attached). The value consists of a record that contains the coordinates of the data point, the ID of the cluster center, and the computed distance.We identify the cluster center that is closest to each data point with a Reduce PACT. The output key-value pairs of the Cross PACT have the ID of the data points as key. Hence, all records (with distance and cluster center ID) that belong to a data point are grouped together. These records are handed to the user code where the record with the minimal distance is identified. This is a minimum aggregation and offers the potential use of a Combiner which performs partial aggregations. The key-value pairs that are generated by the user code have the ID of the closest cluster center as key and the coordinates of the data point as value.
The computation of the new cluster center positions is done with another Reduce PACT. Since its input has cluster center IDs as keys, all pairs that belong to the same center are grouped and handed to the user code. Here the average of all data point coordinates is computed. Again this average computation can be improved by providing a partially aggregating Combiner that computes a count and a coordinate sum. The user code emits for each cluster center a single record that contains its ID and its new position.
Finally, the DataSink (new ClusterCenters) writes the results back into the HDFS.
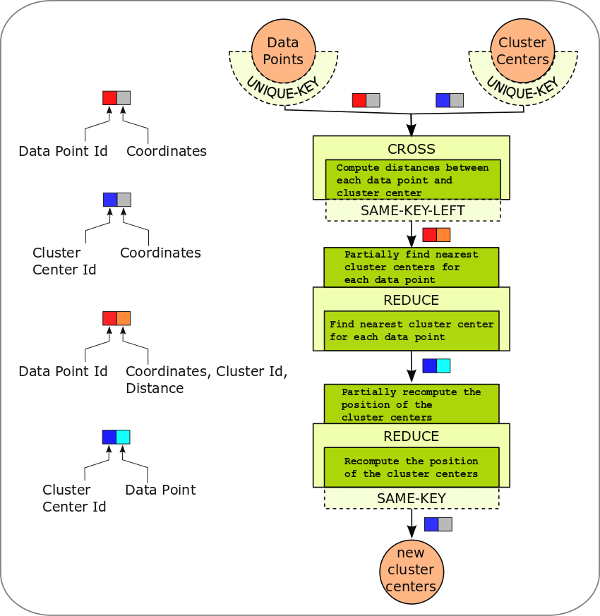
As already mentioned, the PACT program only covers steps 2, 3, and 4. The evaluation of the termination criterion and the iterative call of the PACT program can be done by an external control program.
Program Arguments
Four arguments must be provided to the getPlan() method of the example
job:
-
int noSubStasks: Degree of parallelism of all tasks. -
String dataPoints: Path to the input data points. -
String clusterCenters: Path to the input cluster centers. -
String outputPath: Destination path for the result.
Data Generator
We provide a data set generator to generate data points and cluster centers input files. The generator is implemented as Java class: eu.stratosphere.pact.example.kmeans.KMeansSampleDataGenerator.java in the pact-examples module.
The parameters of the main method of the generator are:
- numberOfDataPoints: The amount of data points to be generated.
- numberOfDataPointFiles: The amount of files in which the data points are written.
- numberOfClusterCenters: The amount of cluster centers to be generated.
- outputDir: The directory where the output files are generated.
Please consult the in-line JavaDocs for further information on the generator.
Pairwise Shortest Paths
Known as Floyd-Warshall Algorithm, the following graph analysis algorithm finds the shortest path between all pairs of vertices in a weighted graph.
A detailed description of the Floyd-Warshall algorithms can be found on wikipedia.
Algorithm Description
Consider a directed graph G(V,E), where V is a set of vertices and E is a set of edges. The algorithm takes the adjacency matrix D of G and compares all possible path combinations between every two vertices in the graph G.
(Pseudocode)
for m := 1 to n
for i := 1 to n
for j := 1 to n
D[[i]][[j]] = min ( D[[i]][[j]], D[[i]][[m]]+D[[m]][[j]] );
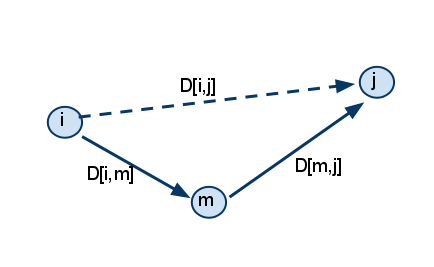
Iterative approach
In order to parallelize the shortest path algorithm, the following steps will be iteratively performed:
Assuming that I(k) is the set of the shortest paths in the k-th iteration.
Generate two key/value sets from the I(k) set:
- S - the set of the source vertices of all paths from I(k)
- T - the set of the target vertices of all paths from I(k)
Perform an equi-join on the two sets of pairs:
- J - the set, consisting of paths, constructed from T and S, where T-th element (path's target) equals the S-th element (path's source)
Union this J joined set with the intermediate result of the previous iteration I(k):
- U = J+I(k)
For all pairwise distances from U set, only the shortest will remain in the I(k+1) set:
- dist(i,j) = min { dist(i,j) | dist(i,m)+dist(m,j) }.
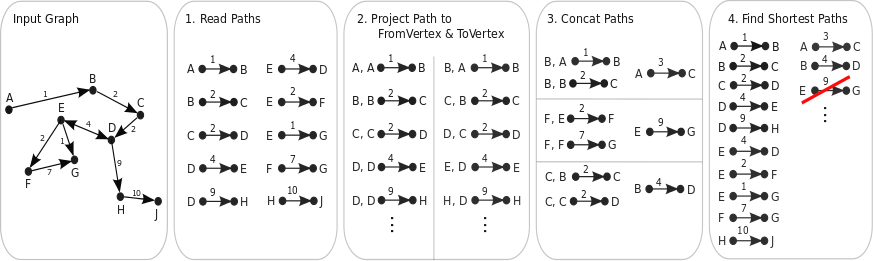
PACT Program
The example PACT program implements one iteration step of the all pairs
shortest path algorithm.
The implementation resides in the following Java class:
eu.stratosphere.pact.example.graph.PairwiseSP.java
in the pact-examples module.
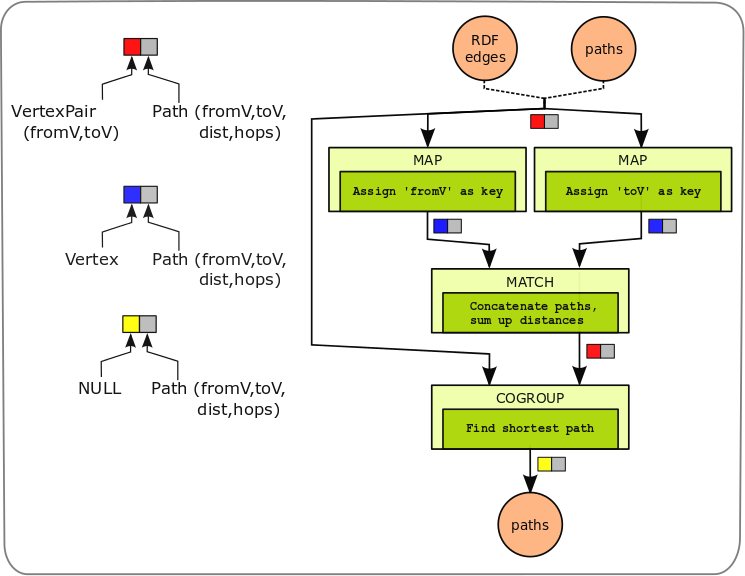
- The PACT program supports two data input formats, namely RDF triples with foaf:knows predicates and our custom path format. The single DataSourceContract of the program is configured with the appropriate InputFormat during plan construction via a parameter. From both input formats, key-value-pairs of the same type are generated. The keys consist of the source and target vertices of the paths. Values is the detailed path information: the source vertex, the target vertex, the path length and a list of all intermediate vertices (hops) between the source and target vertices.
- The following two Map contracts project the input paths on their source and target vertices by setting the keys. The values are not changed and simply forwarded.
- The outputs of both Map contracts are fed into the following Match contract. The Match concatenates all two paths if the start vertex of one path is the end vertex of the other one. The key of the output key-value pair is built from the newly constructed paths' from- and to-vertex. The value is the detailed information of the new path including the updated length and hop-list.
- The CoGroup contract operates on the output set of the Match (recently combined paths) and the original (incoming) paths. The emitted set contains the shortest path (with minimal length) between each pair of from-vertex and to-vertex.
- Finally, a DataSink contract writes the data into the HDFS for the next iteration.
Program Arguments
Four arguments must be provided to the getPlan() method of the example
job:
-
int noSubStasks: Degree of parallelism of all tasks. -
String inputPaths: Path to the input paths. -
String outputPaths: Destination path for the result paths. -
boolean RDFInputFlag: Input format flag. If set to true, RDF input must be provided. Otherwise, the custom path format is required.
Test Data Sets
We provide a small RDF test data set which is a subset of a Billion-Triple-Challenge data set RDFDataSet.tar.gz (77KB, 1.8MB uncompressed). If you want to run the example with (a lot) more test data, you can download a larger subset (or the whole) Billion-Triple-Challenge data set from http://km.aifb.kit.edu/projects/btc-2009/.
Triangle Enumeration
The triangle enumeration PACT example program works on undirected graphs. It identifies all triples of nodes, which are pair-wise connected with each other, i.e., their edges form a triangle. This is a common preprocessing step for methods that identify highly connected subgraphs or cliques within larger graphs. Such methods are often used for analysis of social networks.
A MapReduce variant of this task was published by J. Cohen in “Graph Twiddling in a MapReduce World”, Computing in Science and Engineering, 2009.
Task Description
The goal of the triangle enumeration algorithm is to identify all triples of nodes, which are pair-wise connected with each other.
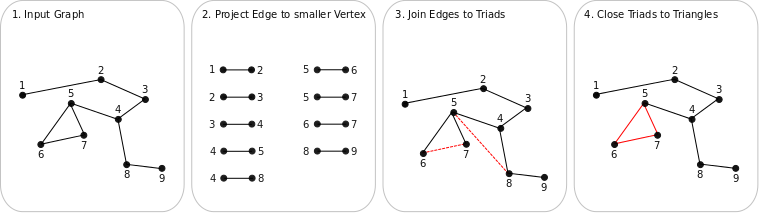
The figure above shows how the algorithm works to achieve that:
- The algorithms receives as input the edge set of an undirected graph.
- All edges are projected to the lexicographically smaller node of both incident nodes.
- Edges that are projected to the same (smaller) node are combined to a triad (an open triangle). Note: The algorithm does only find all triads which are possible candidates for triangles but not all triads of the graph. See for example the triad (1-2, 2-3). It is not found by the algorithm because 2 is the smallest node in (2-3), but not in (1-2).
- For each triad, the algorithm looks for an edge to close the triad and form a triangle. In the example the only triangle (5-6, 5-7, 6-7) is found.
PACT Program
The triangle enumeration example PACT program is implemented in the following Java class: eu.stratosphere.pact.example.triangles.EnumTrianglesRdfFoaf.java in the pact-examples module.
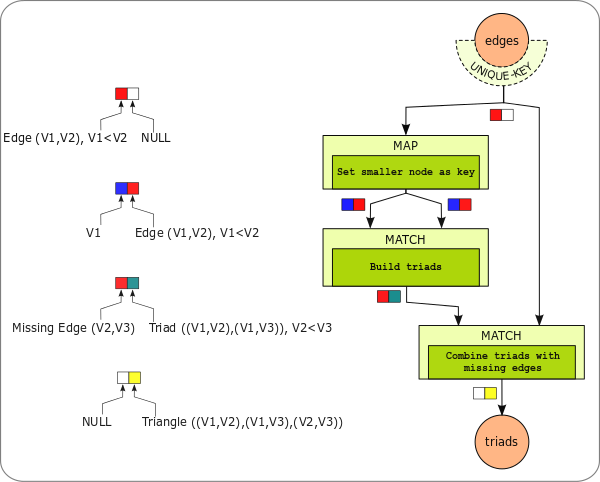
- The triangle enumeration example PACT program supports RDF triples
with
<http://xmlns.com/foaf/0.1/knows>predicates as data input format. RDF triples with other predicates are simply filtered out. The triples must be separated by the line-break character ('\n'). A RDF predicate is interpreted as edge between its subject and object. The edge is forwarded as key with the lexicographically smaller node being the first part of the edge and the greater node the second. The value is set toNULLbecause all relevant information is contained in the key. - The Map contract projects edges to their lexicographically smaller node. This is done by setting the key of the output key-value-pair to the smaller node and forwarding the edge as value.
- The Match contract builds triads by combining all edges that share the same smaller node. Since both inputs of the Match originate from the same contract (Map), the Match is essentially a self-Match. A triad is build by combining both input edges, given that both edges are distinct. In order to avoid duplicate triads, the first edge must be lexicographically smaller than the second edge. The output key-value-pair is built as follows: The key is set to the missing edge of the triad. The lexicographically smaller node becomes the first part of the edge, the greater one the second part. The value is the complete triad (the two edges that the triad consists of).
- The Match contract takes all generated triads and all original edges as input. Both input keys are edges (A-B), A<B. The key of the triad input is the missing edge, the key of the original edge input are the edges themselves. Therefore, Match closes all triads for which a closing edge exists in the original edge set.
- Finally, a DataSink contract writes out all triangles.
Program Arguments
Three arguments must be provided to the getPlan() method of the
example job:
-
int noSubStasks: Degree of parallelism of all tasks. -
String inputRDFTriples: Path to the input RDF triples. -
String outputTriangles: Destination path for the output of result triangles.
Test Data Sets
We provide a small RDF test data set which is a subset of a Billion-Triple-Challenge data set RDFDataSet.tar.gz (77KB, 1.8MB uncompressed). If you want to run the example with (a lot) more test data, you can download a larger subset (or the whole) Billion-Triple-Challenge data set from http://km.aifb.kit.edu/projects/btc-2009/.